Context-Guided Spatial Feature Reconstruction for Efficient Semantic Segmentation
论文地址:arxiv
摘要
背景
语义分割是许多应用中的重要任务,但是在有限计算成本下实现高级性能仍然相当困难。
创新点
提出了 CGRSeg,这是一种基于上下文引导的空间特征重建的高效且竞争力强的分割框架。
设计了一个矩形自校准模块用于空间特征重建和金字塔上下文提取。它在水平方向和垂直方向上捕捉全局上下文,并获取轴向全局上下文以显式建模矩形关键区域。一个形状自校准功能被设计用来使关键区域更接近前景对象。此外,还提出了一种轻量级的动态原型引导头,通过显式类嵌入来改善前景对象的分类。
正文
当前难点
尽管现在已经有网络取得了不错的进展,但是如何使轻量级模型具有更高的分割准确性仍需探索。由于特征表示能力有限,轻量级模型难以对前景对象的边界和类别进行建模,这可能导致边界分割不准确和分类错误等问题。
解决办法
为了解决这些问题,设计了
- 矩形自校准模块(RCM),以改善前景对象的位置建模。
- 动态原型引导(DPG)头,以嵌入类别信息,从而提高前景对象的类别区分能力。
- 上下文引导的空间特征重建网络(CGRSeg),进一步引入金字塔上下文以改善特征表示。该网络包括金字塔上下文提取、空间特征重建和轻量级头。
矩形自核准模型:提高定位前景对象与提取金字塔上下文的能力。矩形自校准注意力是 RCM 的核心组件。使用水平池化与垂直池化来捕捉轴向全局上下文,并生成两个轴向向量。这两个轴向向量相加来建模矩形注意力区域。还设计了一个形状自校准函数来高速矩形注意力的形状,使其更接近前景特征,该函数包括大核条带卷积。还设计了一个融合函数来融合注意力特征并增加局部细节。通过这种方式,RCM 可以使模型在空间特征重建中更加关注前景,并可以捕捉轴向全局上下文来进行金字塔上下文提取。
动态原型引导头旨在通过显式类别嵌入来提高前景对象的分类能力。具体来说,首先将特征投影到类别特征空间。然后,类别空间中的特征和像素空间中的特征相乘以获得动态原型。动态原型可以反映每张图像上所有类别的特征分布。为了进一步嵌入类别信息,动态原型被压缩以获得类别嵌入向量。最后,将类别嵌入向量投影到像素特征空间,并对像素特征进行加权,以增强不同类别之间的区分能力。通过这种方式,DPG 头可以更好地区分不同类别的特征,并提高分类性能。
高效语义分割
实现语义分割有基于 CNN 的轻量级语义分割方法,也有基于 Transformer 的方法。在基于 Tranformer 的方法中也有很多改进与优化,而作者采用了金字塔上下文引导的空间特征重建来提高对前景对象的建模能力。
高效上下文提取模块
注意力机制常用于上下文提取,如坐标注意力与 Gather-Excite。坐标注意力通过水平与垂直池化捕捉轴向全局上下文,并提取坐标关系以增强位置感知。Gather-Exite 高道地聚合来自大空间范围的特征响应,并将池化信息重新分配给局部特征。
而论文中提出的 RCM(关键区域模块)使用加法来建模关键区域,闪设计了形状自核准来校准矩形注意力,使模型更加关注前景特征。
分割头
分割头通常设计用于提高分割网络的性能。
CGRSeg
从前文可知,前景对象建模与金字塔上下文提取对分割很重要。所以设计了一个上下文引导的空间特征重建网络(CGRSeg)。其架构如下所示:
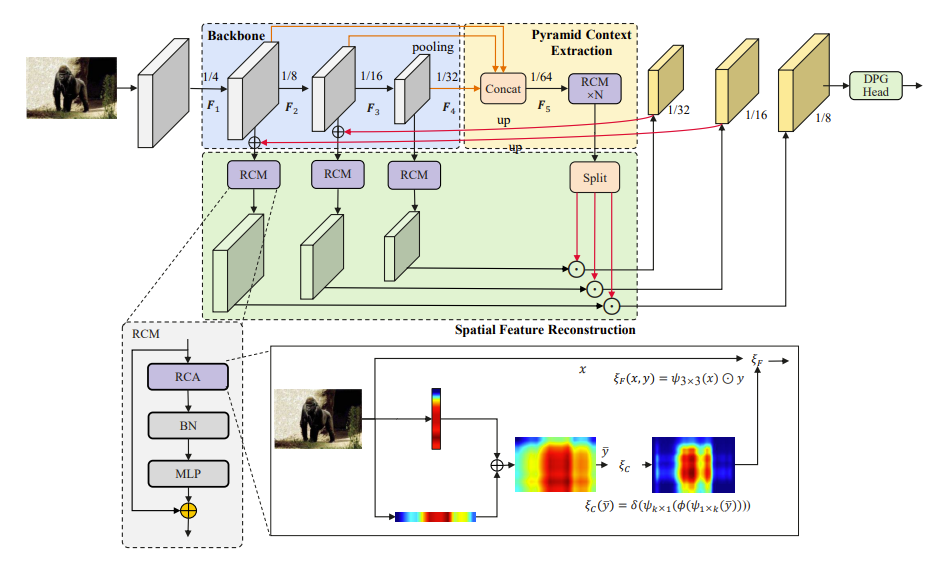
CGRSeg 由三个关键的部分组成:金字塔上下文提取,空间特征重建和一个轻量级头部。为了使模型聚集于前景特征,提出了一个矩形自校准模块(RCM)。它捕捉了用于金字塔上下文提取的轴向全局上下文。提出了一个动态原型引导(DPG), 通过显式类嵌入来提高前景对象的分类。
金字塔上下文提取
RCM 用于提取金字塔上下文,它通过水平和垂直池化来捕捉两个方向的轴向上下文。此外,而使用多层感知器(MLP)进一步增强特征表示。
提出的模型使用了逐步下采样编码器。编码器生成不同尺度的特征,如 $[F1, F2, F3, F4]$,它们的分辨率分别为 $[\frac{H}{4} \times \frac{W}{4}, \frac{H}{8} \times \frac{W}{8}, \frac{H}{16} \times \frac{W}{16}, \frac{H}{32} \times \frac{W}{32}]$。然后,将较低尺度的特征 F 2, F 3 和 F 4 通过平均池化下采样到 $\frac{H}{64} \times \frac{W}{64}$ 的大小,并将它们拼接在一起生成金字塔特征 F 5。F 5 被输入多个堆叠的 RCM 中进行金字塔特征交互并提取具有尺度感知的语义特征。最后,在金字塔特征提取后,特征被分割并上采样到原始尺度。这个过程可以表示为:
$$
P = RCM(AP(F_2, 8), AP(F_3, 4), AP(F_4, 2))
$$
其中,AP (F, x) 表示将特征 F 按因子 x 进行平均池化下采样的操作。P 是具有金字塔上下文的特征。
空间特征重建
为了使解码器特征更集中于前景,RCM 用于重建空间特征。CGRSeg 将来自编码器的低级空间特征与解码器中相应尺度的高级特征融合。融合后的特征通过使用 RCM 进行重建。RCM 捕捉轴向全局上下文来建模矩形关键区域,然后使用形状自校准功能调整注意区域以聚集前景。金字塔特征用于引导空间特征重建,使重建后的特征能够感知多尺度信息。
动态原型引导头部
分割头部生成动态原型以嵌入类信息。类嵌入有助于增强不同类别之间的区别,并提高分类准确性。该模块可以提高前景对象的分类。
矩形自校准模块
可以使模型专注于前景特征。它可捕获轴向全局上下文,用于金字塔上下文提取。该模块包括矩形自校准注意力、批量归一化和多层感知机(MLP)。
矩形自校准注意力采用水平池化和垂直池化来捕获两个方向的轴向全局上下文,并使用广播加法来建模关注的矩形区域。然后,设计了一个形状自校准函数来校准关注区域,使其更接近前景对象。这里,使用了两个大核条形卷积来分别校准水平和垂直方向的注意力图。
首先,使用水平条形卷积来校准水平方向的形状,这调整每一行的元素,使水平形状更接近前景对象。然后,特征通过批量归一化(BN)进行归一化,并通过 ReLU 增加非线性。形状也通过在垂直方向使用垂直条形卷积进行校准。这样,两个方向的卷积可以解耦,能够适应任何形状。
条形卷积的权重是可学习的,从下图可知:高亮区域的形状通过两个具有不同权重的条形卷积进行改变。通过训练,该功能可以学习适当的权重来调整矩形区域到前景对象。
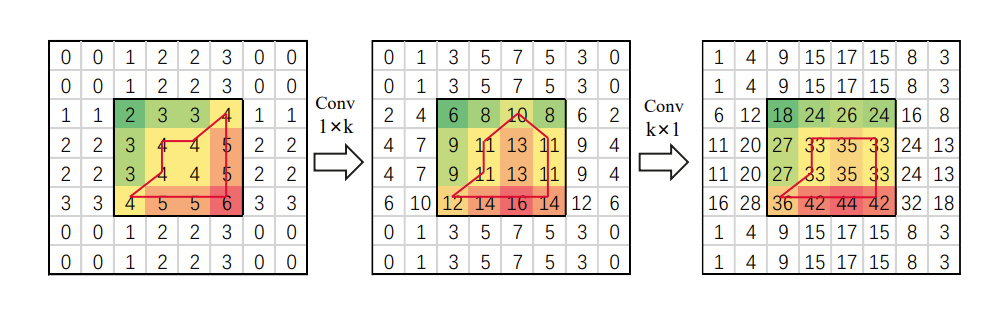
从架构图的可视化结果中也可以看到,矩形自校准注意力确实有效的建模了矩形关键区域,并通过形状自校准函数调整特征,使其更专注于前景。形状自校准函数可以表示如下:
$$
\xi_C(\bar{y}) = \delta(\psi_{k \times 1}(\phi(\psi_{1 \times k}(\bar{y}))))
$$
其中,$\psi$ 表示大核条形卷积,k 表示条形卷积的核长度,$\phi$ 表示批量归一化后跟 ReLU 函数,$\delta$ 表示 Sigmoid 函数。
同时,还设计了一个特征融合函数来融合注意力特征与输入特征:使用 3×3 深度可分离卷积进一步提取输入特征的局部细节,并通过 Hadamard 积将校准后的注意力特征加权到特征上。其公式如下:
$$
\xi_F(x, y) = \psi_{3 \times 3}(x) \odot y
$$
其中,$\psi$ 表示 3*3 的深度可分离卷积,y 是在前一步骤中获得的注意力特征。$\odot$ 表示 Hadamard 积。
此外,还将矩形自校准注意力与 MetaNeXt 结构结合:在矩形自校准注意力之后添加批量归一化和 MLP 来细化特征。最后,采用残差连接进一步增强特征重用。可以在架构图中看到 RCM 的结构,它可以被描述为:
$$
F_{out} = \rho(\xi_F(x, \xi_C(H_P(x) \oplus V_P(x)))) + F_{in}
$$
$\oplus$ 表示广播加法(broadcast addition),$H_P$ 和 $V_P$ 分别表示水平池化和垂直池化。$\rho$ 指的是批量归一化和 MLP。
动态原型引导头
为了改进前景对象的分类,提出了动态原型引导头(DPG 头)。DPG 头生成动态原型以嵌入类别信息。类别嵌入特征被投影到像素特征空间,并通过加权像素特征来增强不同类别之间的区分度。其架构如下所示:
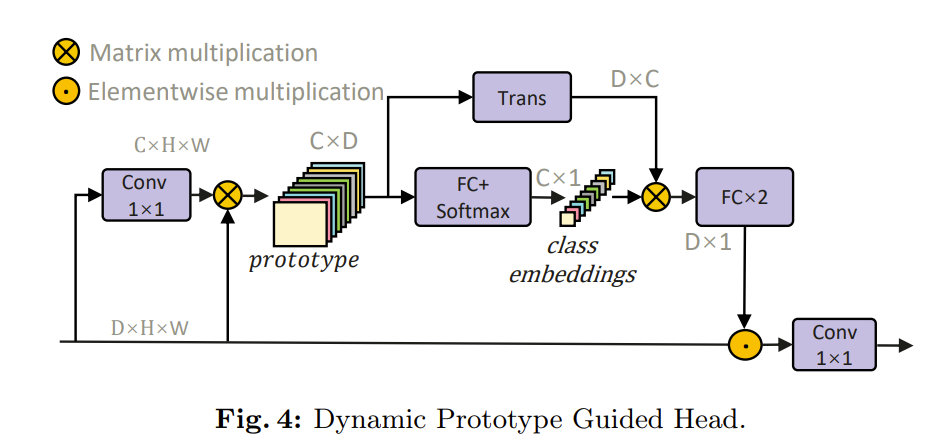
首先,将特征投影到类别特征空间。然后,类别空间中的特征和像素空间中的特征相乘以获得动态原型。动态原型能够反映每张图像中不同类别的特征分布,并遵循输入的动态变化。生成动态原型的过程可以表示为:
$$
F_p = \delta_{D \to C}(F_x) \otimes F_x
$$
其中,$\otimes$ 表示矩阵乘法操作,$F_P$ 表示原型。
接着,DPG 头进一步嵌入类别信息以增强不同类别之间的区分度。应用一个全连接层将原型压缩到 C×1 维度以嵌入类别信息并生成类别嵌入向量,并使用 Softmax 函数将值约束在 0 和 1 之间。类别嵌入向量 1×C 表示每个类别的全局信息。为了将类别嵌入向量投影到像素特征空间,我们将类别嵌入向量与转置的原型相乘。通过类别嵌入增强,新的注意力向量具有更强的区分类别的能力。然后,使用两个全连接层来捕捉注意力向量中的上下文。在两层之间使用层归一化(Layer Normalization)来归一化特征。其过程可以用以下公式表示:
$$
F_{gp} = \text{Softmax}(\delta_{D \to 1}(F_p))
$$
其中,$delta$ 表示全连接层。
最后,注意力向量被加权到像素特征以强调重要特征并增强特征表示。其过程为:
$$
F_o = \delta(\text{ReLU}(\text{LN}(\delta(F_p \cdot F_{gp})))) \odot F_x
$$
其中 LN 和 ReLU 分别是层归一化和 ReLU 激活函数。δ 表示全连接层。$\odot$ 表示广播哈达玛积。计算得到的特征 $F_o$ 随后被送入分类卷积。
模型评估
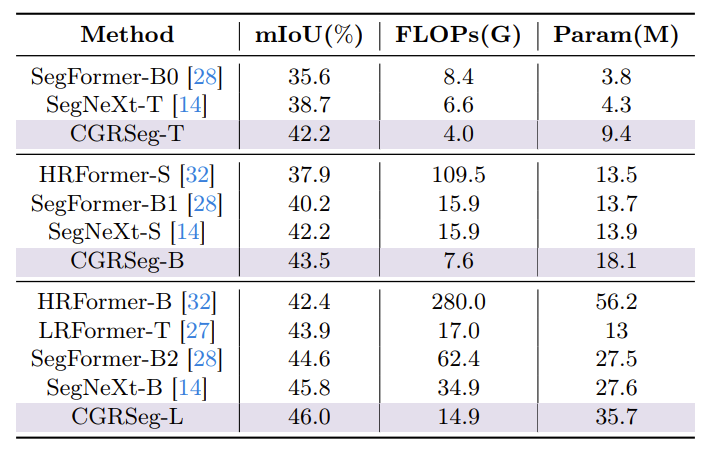
在 ADE 20 K 的结果
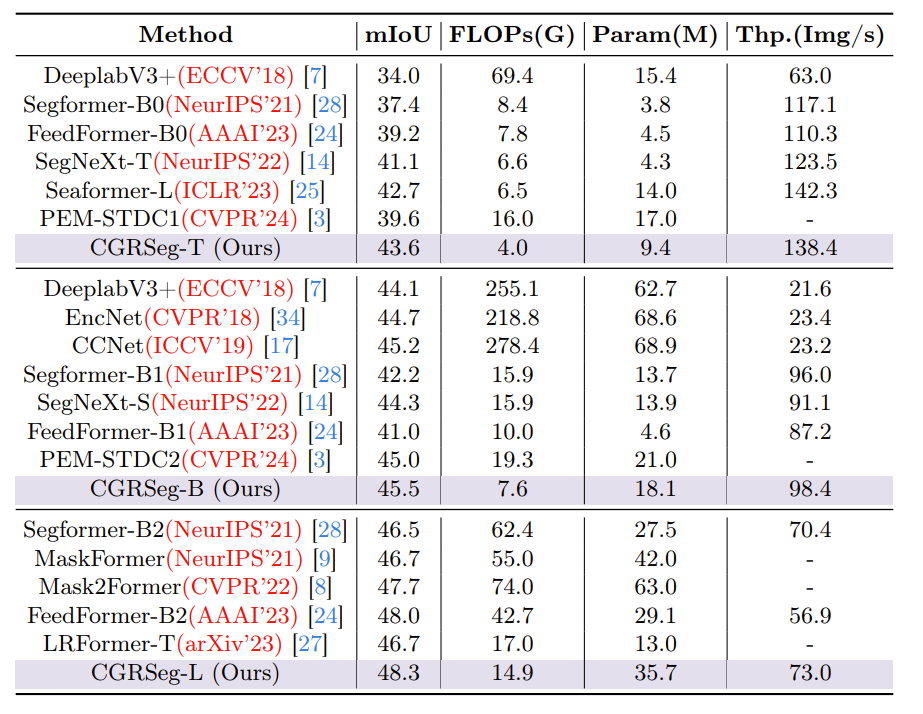
可以得出结论,所提出的 CGRSeg 在相同的实验设置下,可以以更少的计算成本实现更高的性能。
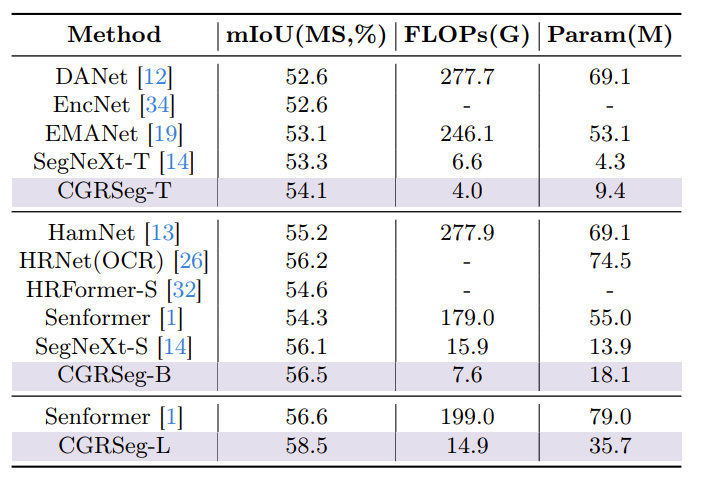
COCO-Stuff 结果
模型性能在计算成本较低的情况下超过了之前最好的方法 SegNeXt
Pascal Context 上的结果
在性能上超过了所有其他对比方法。
消融实验
验证 RCM 和 DPG 头的有效性
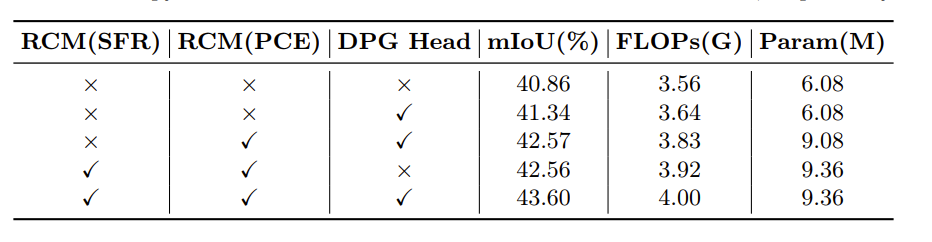
RCM 验证了上下文提取(PCE)与空间特征重建(SFR)的有效性。可以看到,该性能是有效的。
DPG 与其他头的对比
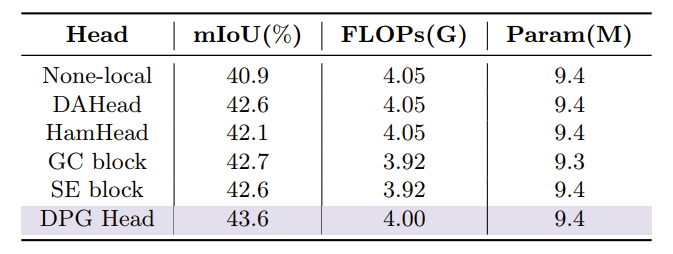
可以看到,DPG 的效果是最好的。
RCA 的有效性
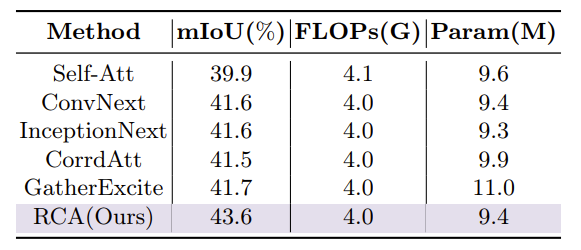
使用其他块替换 RCM,测试出来的准确率均降低了。
与其他主干网络的比较
将主干网络替换为其他的网络后,CGRSeg 仍然可以提高,表明该框架是高效的,可以适应不同的主干网络。

RCA 中使用加法与乘法的对比
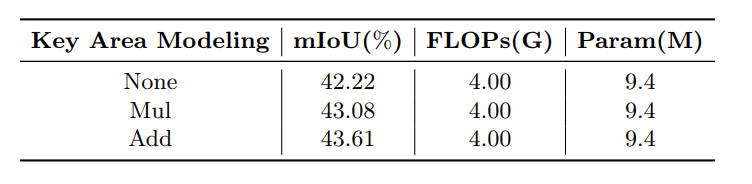
可以看到对关键区域的显式建模可以有效提高分割性能。此外,加法的性能比乘法高
形状自校准函数中卷积核大小的有效性

对比不同卷积核的大小,可以看到,当核的大小增加时,精度也会增加。但是当增加大小时,FLOPs 也会增加,所以只加到 1*11 和 11*1。
RCA 中融合函数的卷积核选择
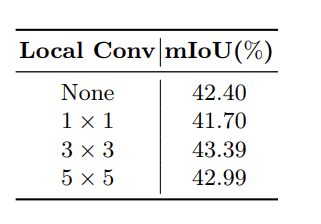
可以看到当大小为 3*3 时,性能最好。