深度学习:算法到实战学习笔记02
本次主题是卷积神经网络的理论知识与pytorch实现过程
笔记内容来源:视频
卷积网络
绪论
卷积神经网络的基本应用
- 图像分类
- 图像检测
- 图像分割
- 人脸识别
- 人脸表情识别
- 图像生成
- 图像风格转化
- 自动驾驭
传统的神经网络与卷积神经网络的区别
深度学习三部曲
- 搭建神经网络结构
- 找到一个合适的损失函数
- 找到一个合适的优化函数,更新参数
损失函数
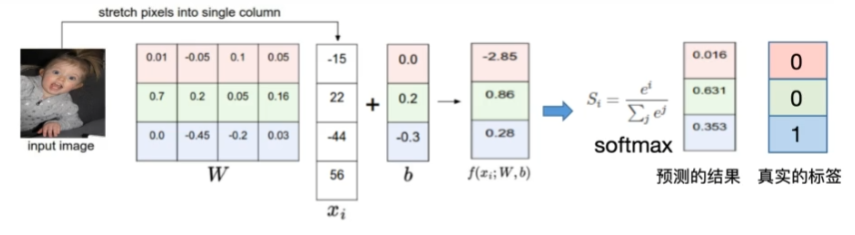
W, b 为神经网络的参数,$x_{i}$ 为图像,$f(x_{i};W,b)$ 为图像经过模型计算后输出的结果。
- 给定 W, b(神经网络的参数)
- 损失函数是用来衡量吻合度的
- 可以调整参数/权重 W,使得映射的结果和实际类别吻合
- 常用的分类损失:交叉熵损失,hinge loss
- 常用的回归损失:均方误差,平均绝对值误差
卷积神经网络的优点
全连接网络处理图像的问题:
- 参数太多:权重矩阵的参数太多->过拟合(学习了太多的细节,比如只认识二哈,不认识金毛)
卷积神经网络的解决方式:
- 局部关联:使用卷积核提取特征,不会让模型过度关注细节。
- 参数共享:卷积核在图像划动的过程中,其参数不会改变。
- 其训练的参数量就为:卷积核的
长*宽+ 1,可以大大减少训练量。
- 其训练的参数量就为:卷积核的
相同之处:神经网络与卷积网络都是层级的结构。
卷积神经网络的特性
很多层 (Compositionality)
- 通过多个层次的特征组合,逐步构建出复杂的表示
- 每一层从前一层中提取特征,在最后的层中,可以提取出比较高级的主义特征。
局部性与图像的平稳性
- 局部性:卷积核只在图像的局部区域上滑动并进行运算,每个神经元只处理输入图像的一个小区域
- 可以让网络捕捉局部特征,比如边缘,角和小的图案
- 图像的平稳性:图像的统计特性在空间上是平稳的,即不同位置的局部区域可能具有相似的特征
- 同一个卷积核可以在整个图像上共享,可以大大减小参数数量并提高了模型的训练效率
池化(Invariance of Object Class to Translations)
- 通过对局部区域取最大值或平均值来缩小特征图的尺寸,这种操作可以减少特征图的空间分辨率,同时保留重要的特征。
- 不变性:池化操作使得网络对输入图像的小幅平移具有不变性。即使图像中的物体稍微移动,池化后的特征图依然可以保持相对稳定。
- 最大池化有助于提取最显著的特征,平均池化则可以平滑特征图
典型使用的场景:在多个卷积层之后,通常会加一个池化层来逐渐减少特征图的尺寸。例如,在一个典型的卷积神经网络中,可能会有两到三个卷积层后接一个池化层的结构。
基本的组成结构
卷积
一维卷积
- 一维卷积经常用在信号处理中,用于计算信号的延迟累积。
定义
卷积是对两个实变函数的一种数学操作。
在图像处理中,图像是以二维矩阵的形式输入到神经网络的,因此需要使用二维卷积。
二维卷积的工作过程是,卷积核与图像对应的位置求内积。
- 其公式为 $y=WX+b$,W 为卷积核,X 为图像参数,b 为偏置项
如果输入的有三个 channel,则对应的卷积核的 channel 也会有三个,然后对应的做卷积,然后三个 channel 的值相加,再加上对应的偏移后即可得出特征图中对应位置的值。
- 如果有两个卷积核,则特征图也会有两个,相互独立。
概念
- 输入:输入的二维矩阵
- 卷积核/滤波器:就是卷积核
- 权重:卷积核中每一个单位的值
- 感受野:卷积核在每次卷积时所使用输入的范围
- 特征图:卷积后输出的图
- 步长:卷积核在卷积完了一次后,移动的距离
- 如果步长无法正常匹配输入,则会用到 padding 来对图像进行填充,使其步长与输入可以匹配。
- padding
- channel
- 是特征图的厚度,其大小于卷积核的个数保持一致
- output
输出的特征图的大小:
无 padding:
$$
(N-F)/stride+1
$$
N: 输入的图像的长度,F:卷积核的长度,stride:步长
有 padding:
$$
(N+padding*2-F)/stride+1
$$
池化
- 保留了主要特征的同时减少参数和计算量,防止过拟合,提高了模型泛化能力。
- 一般处于卷积层与卷积层之间,全连接层与全连接层之间
- 不会改变 channel 的个数
- 模型参数为 0,其相当于数据运算,不需要运算。
- 池化层的步长一般为池化核的大小
类型:
- Max pooling:最大值池化
- Average pooling:平均池化
在分类的任务中,更加偏向于使用最大值池化。
概念:
- filter:池化层的大小
- 步长:每次移动的距离
全连接
全连接层
- 两层之间所有神经元都有权重链接
- 通常全连接层在卷积神经网络尾部
- 全连接层参数量通常最大
卷积神经网络典型结构
AlexNet
其之所有可以成功,主要是因为:
- 大数据训练:
- 非线性激活函数:ReLU
- 防止过拟合:Dropout, Data augmentation
ReLU
优点:
- 解决了梯度消失的问题(在正区间)
- 计算速度特别快,只需要判断输入是否大于 0
- 收敛速度远快于
sigmoid
DropOut
- 在训练时随机关闭部分神经元,测试时整合所有神经元
- 可以用于防止过拟合
数据增强
- 平移,翻转,对称
- 随机裁切
- 水平翻转,相当于样本倍增
- 改变 RGB 通道强度
- 对 RGB 空间做一个高斯扰动
分层解析
- 第一次卷积:卷积,ReLU,池化
- 第二次卷积:卷积,ReLU,池化
- 第三次卷积:卷积,ReLU
ZFNet
- 网络结构与 AlexNet 相同
- 将卷积层 1 中的感受野大小由 11 x 11 改成 7 x 7,步长由 4 改为 2
- 卷积层 3,4,5 中的滤波器个数由 384,384,256 改为 512,512,1024
VGG
- VGG 是一个更深的网络
- 变成了 16 层-19 层
GoogleNet
- 网络总体结构:
- 网络包含 22 个带参数的层(如果考虑 pooling 就是 27 层),独立成块的层总共约有 100 个
- 参数量大概是 AlexNet 的 1/12
- 没有 FC 层
Inception 模型
初衷:多卷积核增加特征多样性
通过 pedding 技术,将不同的卷积核串的输出内容连起来。
缺点:随机模型的加深,channel 的个数也会不断的变高,会使得计算量很大。
Inception v 2 模型
解决思路:通过插入 1*1 的卷积核来进行降维
Inception v 3 模型
- 进一步对 v 2 的参数数量进行降低
方法:
- 将一个 5 x 5 的卷积核用两个 3 x 3 的卷积核代替。(这两种方式所表示的感受野的大小一样)
好处: - 降低了参数量(
5*5+1->(3*3+1)*2) - 增加了非线性激活函数:增加非纯属激活函数使网络产生更多独立特征,表征能力更强,训练理快。
ResNet
- 残差学习网络
- 深度有 152 层
残差
目标:去掉相同的主体部分,从而突出微小的变化
- 可以被用来训练非常深的网络
- 不存在梯度消失的情况
- 即使在训练时,出现某层网络的输出为 0 的情况,训练依然可以进行下去
->模型可以自动调节深度。
- 即使在训练时,出现某层网络的输出为 0 的情况,训练依然可以进行下去
传统网络:
数据经过网络处理后直接给了下一层。x -> conv -> relu ->conv -> f(x)
残差 block:
数据经过网络处理后,会再加上输入的数据,再给下一层。x -> conv -> relu ->conv -> f(x) + x。
使用pytorch编写代码
Pytorch API 调用方法
制作数据集
方法一 :从远程下载
pytorch 中有很多常见的数据集,可以调用 torchvision.datasets 把数据由远程下载到本地。
语法:
1 | torchvision.datasets.xxx(root, train=True, transform=None, target_transform=None, download=False) |
解释:
- xxx:数据集的名字
- root:保存的目标文件夹
- train,如果设置为True,从training.pt创建数据集,否则从test.pt创建。
- transform:一种函数或变换,输入PIL图片,返回变换后的数据
- target_transform:一种函数或变换,输入目标,进行变换。
- download:设置为true时,如果数据集不存在,会自动下载。
对于数据的预处理,可以使用transforms.Compose()将多个变换连接在一起。
可以使用的变换有:
transforms.ToTensor():将 PIL 图像或 numpy 数组转换为 PyTorch 的张量(Tensor)。同时,还会将图像的像素值自动的映射到[0, 1]。torchvision数据集输出的范围为[0, 1]之间的PILImage。transforms.Normalize(mean, std):用于对图像数据进行标准化处理。标准化的目的是使每个通道的像素值具有零均值和单位标准差,这有助于加快模型训练速度和提高模型的收敛性。- mean:每个通道的均值
- std:每个通道的标准差
transforms.CenterCrop(x):从输入图像的中心裁剪出一个指定大小的图像。这样可以简化数据处理并使得网络架构的一些操作可以正确运行。transforms.RandomCrop(x, padding = y):先对图像填充 y,再对图像进行随机裁剪,裁剪后的大小为x * x。transforms.RandomHorizontalFlip(): 对图像进行随机水平翻转
方法二:从本地文件夹构建数据集
使用 ImageFolder 函数完成构建。
ImageFolder会递归地遍历指定目录中的所有子目录。每个子目录的名称将被视为一个类别标签。
ImageFolder会自动为每个类别分配一个整数标签。例如,如果有两个子目录'cats'和'dogs',它们可能会被映射为0和1。- 对于每个图像文件,
ImageFolder会使用 PIL 库加载图像,并应用指定的变换(transform)。
用法:
1 | torchvision.datasets.ImageFolder(root, transform=None, target_transform=None, loader=default_loader, is_valid_file=None) |
参数:
- root: 数据集的根目录,该目标下应该包含按照类别组织的子目录,每个子目录包含该类别的图像。
- transform:一个函数或变换,应用于每个图像样本(输入)
- target_transform:一个函数或变换,应用于每个目标(标签)
- loader:一个函数,用于加载给定路径的图像。
- is_valid_file:一个函数,用于检查文件是否为有效文件。
从数据集加载数据
使用 torch.utils.data.DataLoader(dataset, batch_size, shuffle, ..) 来加载一个数据
参数:
- dataset: 使用的数据集,必须是
Dataset的子类实例。 - batch_size:每个批次加载的数据量。默认为 1。
- shuffle: 是否在每个 epoch 开始时打乱数据。默认为 False。推荐为true。
其他可用的参数: - sampler: 自定义采样策略。如果提供了这个参数,shuffle 参数将被忽略。
- num_workers: 用于数据加载的子进程数量。默认为 0,表示数据将在主进程中加载。增加这个值可以加快数据加载速度。
- collate_fn: 合并样本列表以形成一个 mini-batch 的函数。默认情况下,它会将样本堆叠成一个 mini-batch。
- pin_memory: 如果设置为 True,数据加载器会将张量复制到 CUDA 固定内存中。对于使用 GPU 的情况,可以加快数据转移速度。
- drop_last: 如果数据集大小不能被 batch_size 整除,是否丢弃最后一个不完整的批次。默认为 False。
- timeout: 从数据加载中获取批次的超时时间(以秒为单位)。默认为 0,表示没有超时。
编写神经网络
在 pytorch 中,可以通过自定义一个神经网络来实现非线性的神经网络模型。
定义一个神经网络的框架如下:
1 | class XXX(nn.Module): |
主要会使用的网络层
- 卷积层(
Conv2d)- 是一个卷积核
- 批归一化层(
BatchNorm2d)- 用于标准化卷积层的输出,使其加速训练,保持输入分布稳定,有正则化的效果
- 池化层(
MaxPool2d或AvgPool2d)- 减少特征图的尺寸,同时保留重要的特征,降低计算复杂度,减少过拟合。
组合方式:卷积层 + 批量归一化层 + 激活函数 + 池化层
卷积的用法:
- 可以使用
1*1的卷积核来改变通道数,从而控制模型的复杂度 - 可以将一个
n*n的卷积拆成1*n后接n*1的两个小卷积,计算时间复杂度会由o(n^2)变成o(2n)
直接加载经过预训练处理的网络模型
1 | torchvision.models.xxx(pretrained=xxx) |
参数:
pretrained:这个参数指定预训练的权重。如果设置为True,则模型会加载训练好的权重,而不是随机初始化权重。这使得模型可以直接用于迁移学习或作为特征提取器。
可以使用的模型有:VGG 系列,ResNet 系列,DenseNet 系列等。
冻结经过预训练的网络的某几层
可以通过 requires_grad = False 的方式来冻结网络层,从而达到不训练的目的。
1 | # 假设当前有模型model_vgg,要将其所有的层都冻结,只需要 |
param 代表 model_vgg 模型中的一个参数。一个模型通常包含多个参数,这些参数是模型的权重和偏置。
修改经过预训练的模型
例:修改 vgg 模型的分类器的第 6 层与第 7 层:
1 | # 修改第6层,将 nn.Linear(4096, 1000)改成 nn.Linear(4096, 2) |
数据的处理
view 操作
view 操作一般出现在 model 类的 forward 函数中,可以改变输入或输出的形状。
用法: view(batch_size, feature_size)。
参数:
batch_size:一批的大小feature_size:特征数
一般来说,只要一写入一边的参数,另一边写 -1,计算机会自动计算该值。
view 的作用
卷积层的输出通常是一个多维张量(即具有多个通道、高度和宽度)。然而,全连接层(线性层)期望输入是一个二维张量,其中一个维度是批量大小,另一个维度是特征数。因此,在输入全连接层之前,需要将卷积层的输出展平。
常用写法
out.view(out.size(0), -1)
可以将任意批量的多维数据展开成二维数据。
torch.max()
torch.max(tensor, dim) 可以返回传入 tensor 的最大值,dim 表示在指定维度上的最大值。如果指定了 dim,则返回会有两个数值,一个是最大值,一个是最大值的索引。
因此,可以通过该函数知道最大值的位置。通过该函数,则可以很轻松的知道使用 softmax 或 log_softmax 作为分类器的模型的判别结果。
打开一个本地 json 文件并赋值到一个变量中
1 | with open('文件路径') as f: |
训练与评估模型
一般来说,训练模型与检测模型的代码会封装成一个函数。
模型在训练时,需要将模型设置为训练模式,因为有些层在不同模式下的表现不同:
1 | model.train() |
常见的训练函数的框架有:
1 | # 训练函数 |
模型在评估时,要设置成评估模式,当模型设置为评估模式时,会禁用 dropout 层等。
常见的模式有:
1 | def test(model): |
数据可视化
torchvision.utils.make_grid() 可以将多张图像组合成一张网络网。
如果一个图片经过了预处理(翻转,归一化等操作),则需要进行反预处理。
以下是几个例子
1 | def imshow(img): |
1 | def imshow(inp, title=None): |
输出预测正确的图像
1 | # 单次可视化显示的图片个数 |
使用 pytorch 编写代码
构建复杂网络
以编写 Inception A 模块为例:
1 | class InceptionA(nn.Module): |
在构建卷积网络时,一定要关注输入图片的尺寸与输出图片的尺寸。上一层的输出的尺寸一定要与下一层输入的尺寸一致。尺寸的计算方法可以在上文找到。
残差神经网络编写
残差神经网络的编写方法和其他网络没有什么不同,唯一需要注意的是:残差神经网络的输出结果是经过 网络层计算后的结果+输入的结果。而网络层可能会改变输出的通道数,因此,需要使用shortcut() 来调整输入数据的通道数(其本质是一个1*1的卷积网络),使其与网络层的输出的通道数一致。
1 | class BasicBlock(nn.Module): |
课后作业
代码练习
- 使用卷积网络来识别mnist手写数字
图像经过卷积以后,其大小会发生变化,比如图像的尺寸,图像的通道数等。上层网络在连接下层网络时,要确保这些数据都一样。否则代码在运行的过程中会报错。如果要改变通道数,只需要改变out_channels的值即可。而尺寸的改变则是因为卷积操作本身。其计算公式为:
无填充:$y=(x-z)/stride+1$。$y$为输出图像的尺寸的边长,$x$为输入图像的尺寸的边长,$z$为卷积核的大小
有填充:$y=(x+padding*2-z)/stride+1$。
使用CNN分类CIFAR10
这里模型的变化和上面没有太大的差别。唯一的区别是:原来输入的图像的通道是1,表示灰度,而这次输入的图像是3,表示红,绿,蓝。因此,在代码中的区别体现在:分类mnist数据集时,第一层的通道数为1;而分类CIFAR10数据集时,第一层的通道数为3。
训练卷积网络与训练线性网络的训练部分的代码一样,都是先计算损失,然后反向传播,再用优化器进行优化。
使用VGG分类CIFAR10
- 这里的构建网络的过程与上方差不多,唯一的区别就是使用到了循环来构建一个网络,因此我认为这个代码的重点是对于图像的预处理部分。
- 这里的图像的预处理使用到了
RandomCrop:随机裁剪,同时为了保证在裁剪后大小与原图像一致,这里进行了先对图像填充至40*40的大小。RandomHorizontalFlip:随机翻转,对于计算机来说,一个图像经过翻转后就是一个全新的图像。因此通过使用这个预处理,让数据集的数量翻倍。ToTensor:将 PIL 图像或 numpy 数组转换为 PyTorch 的张量(Tensor)Normalize:将图像进行标准化处理,可以加速训练,加速收敛。这个值是经过别人计算后得出来的,直接写就可以了。
- 此外,在加载数据时还用到了
shuffle:这个可以打乱图片的加载顺序,可以防止模型产生对图片出现顺序的依赖。
问题
dataloader ⾥⾯ shuffle 取不同值有什么区别?
当shuffle的值设置为true时,数据加载器会在每个训练周期开始前随机打乱数据集,而设置为false时,则不会打乱数据集。通过打乱数据集,模型在每个周期内看到的数据顺序都是不同的,可以帮助模型更好的泛化没见过的数据。还可以防止模型产生对图片出现顺序的依赖,防止模型过拟合。
transform ⾥,取了不同值,这个有什么区别?
transform是对图片的一个转换操作,transform可以取得不同的值来完成对图片的不同操作,比如CenterCrop,RandomCrop,RandomHorizontalFlip,ToTensor,Normalize。其中,ToTensor是必需要有的,这个用于将PIL图像(使用datasets下载的数据集都是PIL图像)变成pytorch可以处理的数据类型。其他的几个变换都是为了提高模型的泛化能力,提高模型的训练速度,防止模型过拟合(一个图像只要经过翻转,裁剪,平移等操作后,对于计算机来说都是一个全新的图像)。
epoch 和 batch 的区别?
一个epoch对应使用一个数据集完整的训练过一个模型一次。而数据集太大时,比如500000个图像,那么计算机中没有足够的空间来一次性存放这么多的数据。此时可以将一个大的数据集分解成为若干小组,一个小组称为一个batch,多个batch组合成一个完整的数据集。
1x1的卷积和 FC 有什么区别?主要起什么作⽤?
1x1的卷积是卷积核大小为1的卷积层,主要的作用是对于数据的升维或降维(调整通道数)。
FC是全连接层,主要的作用是对信息的整合,常用于分类(如果用于分类,则最后一层的结点数等于类别的数量)。FC中的每个结点都会连接上一层的所有的结点。如果上一层有n个结点,这一层有m个结点,那么会有n*m个连接。一个卷积网络的连接数量大多在全连接层上。
residual leanring 为什么能够提升准确率?
残差神经网络的特点是,输出的数据等于输入的数据加经过网络处理的数据。因此,即使当网络处理的数据为0时,输出依然有效(相当于数据跳过了当前的一层网络)。使用这种方式可以连接更深层次的网络结构,防止出现性能下降的问题。此外,通过跳跃连接,梯度可以反向传递到更前面的层,缓解了梯度消息的问题。
代码练习⼆⾥,⽹络和1989年 Lecun 提出的 LeNet 有什么区别?
LeNet模型参考:wiki
LeNet的结构与代码练习二的网络结构基本一致。区别是:
- LeNet使用平均池化层,而代码练习二使用的是最大池化层
- LeNet使用
sigmoid作为激活函数,而代码练习二使用ReLU作为激活函数
代码练习⼆⾥,卷积以后feature map 尺⼨会变⼩,如何应⽤ Residual Learning?
可以使用1*1的卷积网络,将feature map的尺寸调整到与输入数据一样的大小后再相加得到输出结果。
有什么⽅法可以进⼀步提升准确率?
- 可以使用迁移学习,比如vgg16网络的迁移学习:将除了最后一层外的所有网络层全冻结,然后修改最后一层使其符合要求
- 在每个卷积层下都加上批量归一化层:可以加速训练,标准化卷积层的输出
- 增加数据集:数据增强:图像翻转,平移,旋转等
- 增加训练的epoch
- 构建更加复杂的网络模型