深度学习的学习笔记05
MobileNet,ShuffleNet与SENet
ShuffleNet参考视频:bilibili
SENet参考文章:文章
MobileNet V1 & V2 &V3
简介
传统网络缺点
- 内存需求大,运算量大,无法在移动设备以及嵌入式设备上运行。
MobileNet 网络专注于移动端或嵌入式夜中的轻量级 CNN 网络。其在准确率小幅降低的前提下大大减少了模型参数与运算量。
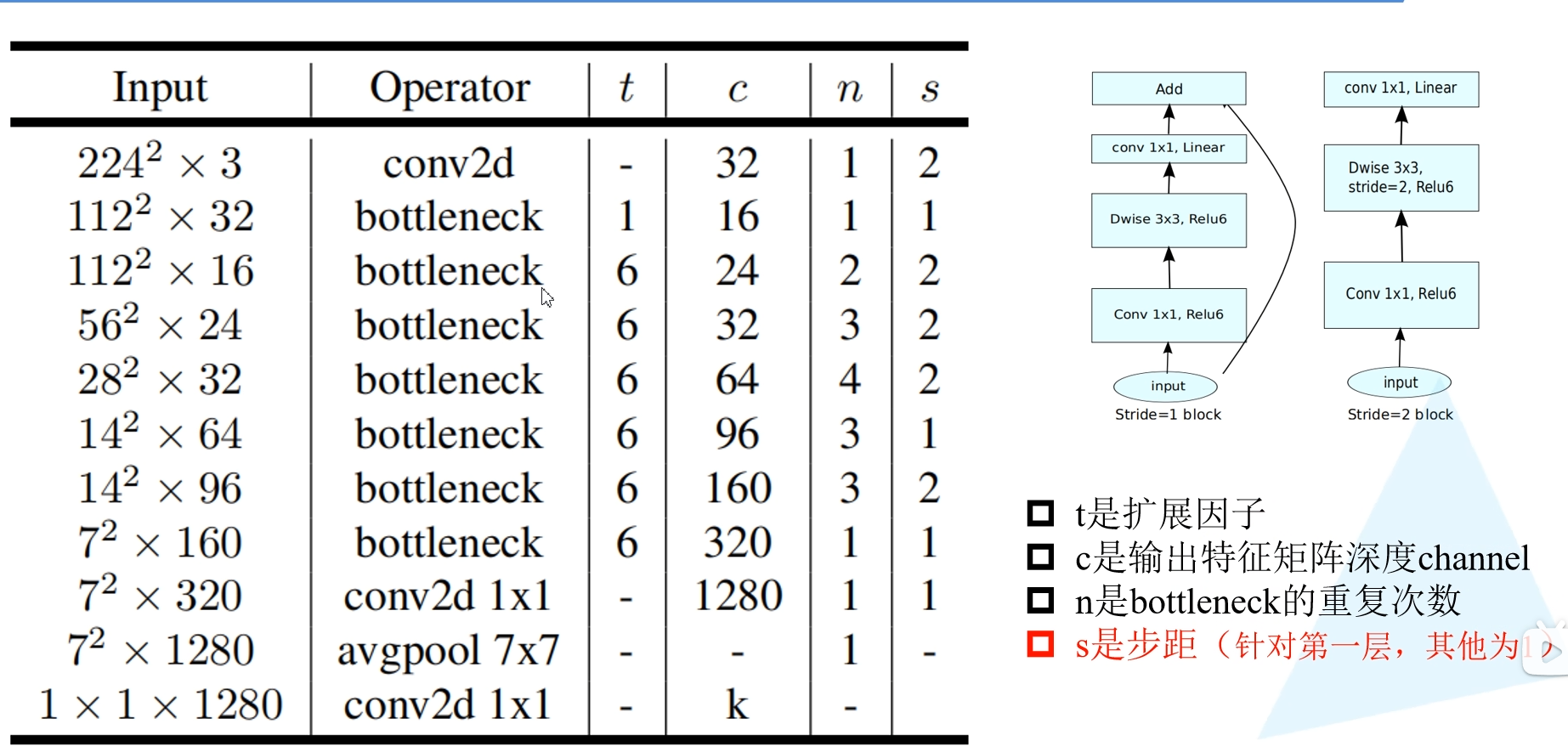
MobileNet V1
改进
DW 卷积(Depthwise Conv)
作者认为:1x1卷积核的计算量在某些情况下可能会被认为是较高的,因为它需要对每个输入通道进行独立的线性变换。所以提出了DW卷积。
传统的卷积:
- 卷积核 channel=输入特征矩阵 channel
- 输出特征矩阵 channel=卷积核个数
DW 卷积:
- 卷积核 channel=1
- 输入特征矩阵 channel=卷积核个数=输出特征矩阵 channel
PW 卷积:
- 就是一个普通的卷积,不过卷积核大小为 1
计算量
变量的含义:
- $D_{F}$:输入特征矩阵的高与宽
- $D_{K}$:卷积核的大小
- $M$:输入特征矩阵的深度
- $N$:输出特征矩阵的深度
则:普通卷积的计算量为:$D_{K}D_{K}MND_{F}*D_{F}$
而 DW+PW 卷积:$D_{K}D_{K}MD_{F}D_{F}+MND_{F}*D_{F}$
自定义参数
- $\alpha$:卷积核的倍率,用于控制卷积核的个数
- $\beta$:输入图像的分辨率
MobileNet V2
特点
相对于 MobileNet v1,其准确率更高,模型更小。
改进
Inverted Residuals(倒残差结构)
原始的残差结构(使用 ReLU 激活函数):
1*1卷积降维3*3卷积1*1卷积升维
倒残差结构(使用 ReLU 6 激活函数):
1*1卷积升维3*3卷积 DW1*1卷积降维
ReLU 6 激活函数:
$$
y = ReLU6(x) = min(max(x, 0), 6)
$$
ReLU 激活函数对低维特征信息会照成比较大的损失,而对于高维的信息,其损失不会太大,所以对于倒残差结构的最后一个卷积层,使用的并不是 ReLU 激活函数,而是线性的激活函数。
卷积核的形状:
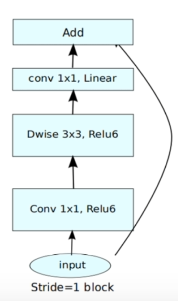
当 stride=1 且输入特征矩阵与输出特征矩阵的 shape 相同时,才会有 shortcut 连接
整体的结构:
t:用于升维的倍率
MobileNet V3
改进
- 重新设计了 Block
- 使用 NAS 搜索参数
- 重新设计耗时层结构
相比 V 2,耗时更少,准确率更高。
更新 Block
加入了注意力机制(SE 模块)
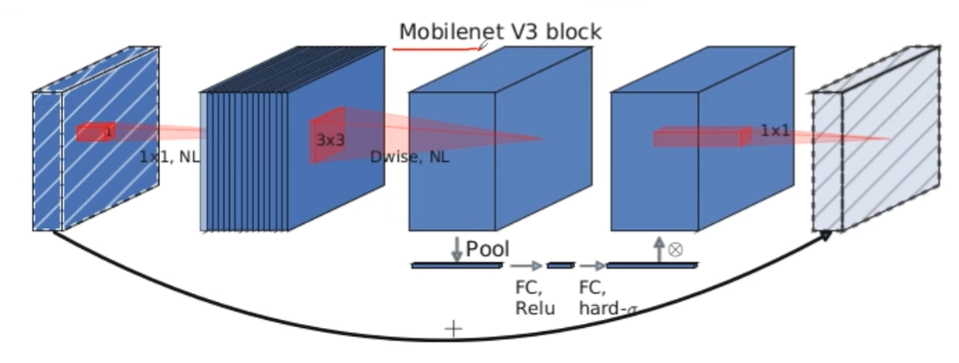
先使用平均池化层得到元素,然后对这些元素通过两个全连接层得到一个输出的向量。第一个全连接层的结点的个数为输入 channel 的 1/4。第二个全连接层的结点的个数与 channel 保持一致。得到一个输出的向量后,将每一个 channel 中的元素,都与对应的元素相乘,得到一个新的数据。
1*1 的卷积处没有使用激活函数。
只有当 stride==1 且 input_c == output_c 才有 shortcut 连接
重新设计耗时层结构
- 减少第一个卷积层的卷积核的个数(由 32 减为 16)。论文中说,准确率不会变
- 精简 last Stage
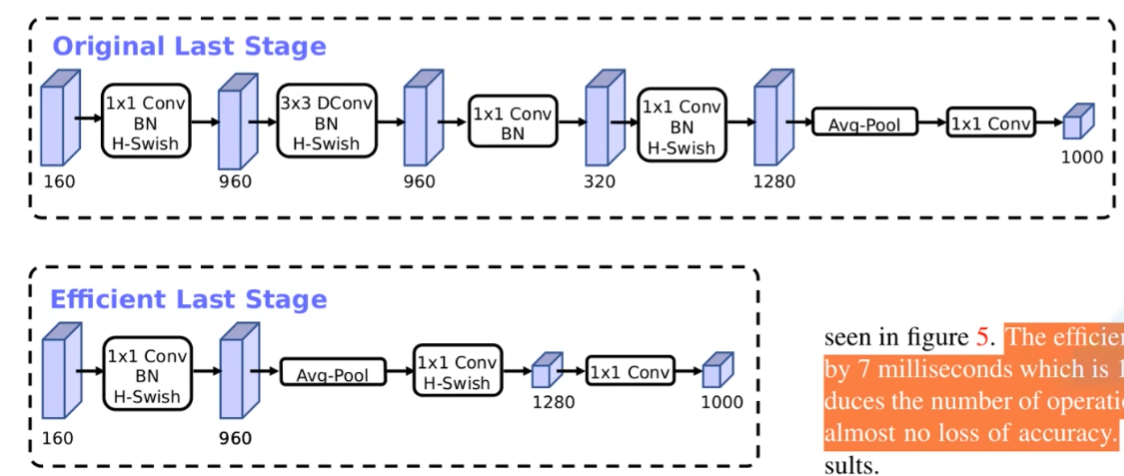
将 original last stage 精简为 efficient last stage,论文中说,准确率不变,但是速度快了很多。
重新设计激活函数
常用的激活函数是 swish(x) 。
$$
swish(x)=x*\sigma(x)
$$
问题:
- 计算,求导复杂
- 对量化过程不友好
改进:h-swish
h-sigmoid:
$$
h-sigmoid=\frac{ReLU6(x+3)}{6}
$$h-sigmoid 激活函数可以在一定程度上代替 sigmoid 函数,所以,h-swish 函数可以写成:
$$
h-swish(x)=x*(h-sigmoid(x))=x\frac{ReLU6(x+3)}{6}
$$h-swish 函数与 swish 函数几乎相等,但是 h-swish 的速度要快一些。
网络结构
MobileNet V3 的结构如下:
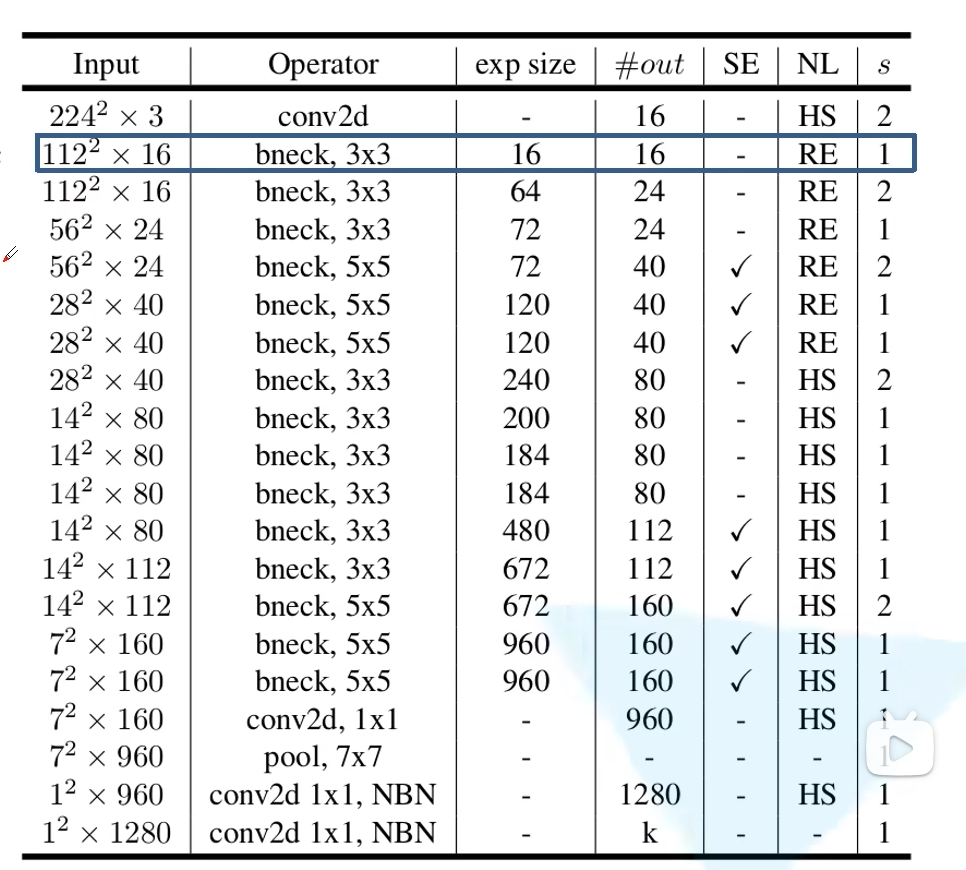
- input:输入数据的 shape
- operator:操作
- exp size: 第一个升维的卷积要升到的维度
- out: 输出的 channel
- SE:是否使用注意力体制
- NL: 激活函数(HS: h-swish)
- s: 步距
ShuffleNet V1 & V2
ShuffleNet V1
特点
- 提出了 channel shuffle 的思想
- 在 ShuffleNet Unit 中使用的全是 GConv 与 DWConv
Channel shuffle
原理:GConv 虽然可以减少参数与计算量,但是 GConv 中不同组之间信息没有交流。所以,假设有 n 组,则将每组的输出分为 n 份,然后将每组的第 i 份组成一个新的组,作为第 i 组的输出。
改进 Unit
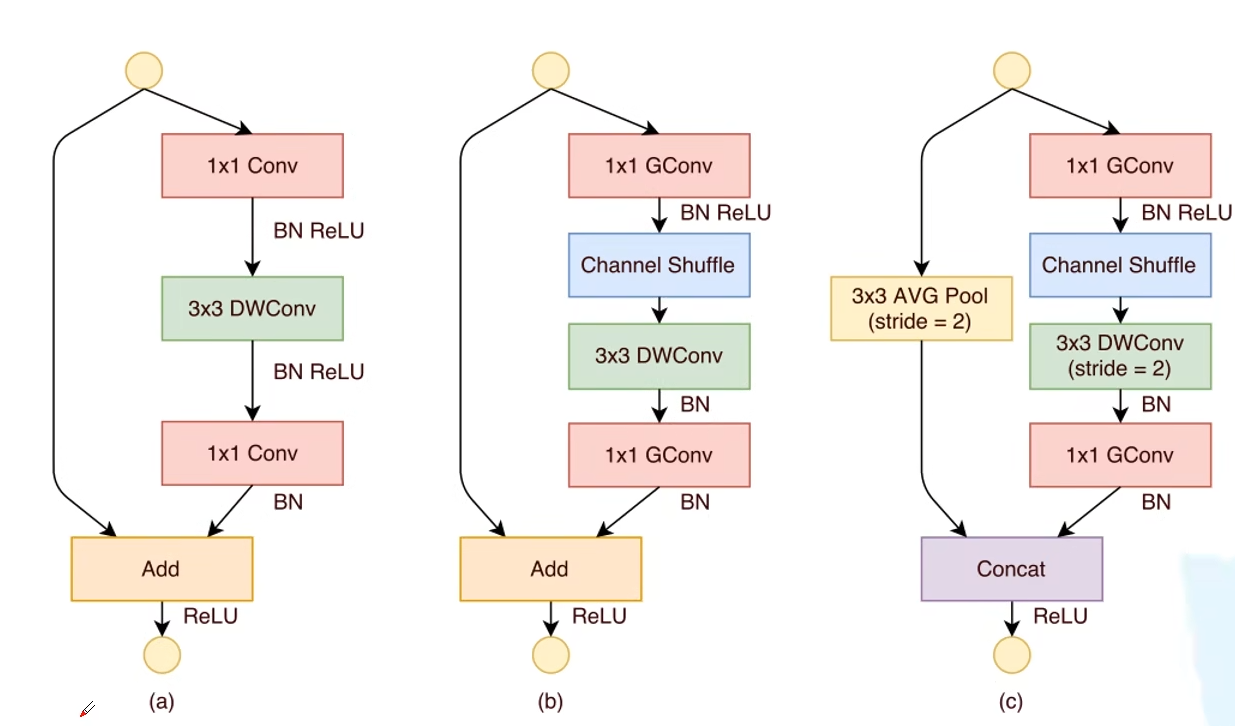
b:stride 为 1 时。c:stride 为 2 时。
由于计算的大部分时间都被 1*1 的卷积网络占用了,所以将 1*1 的卷积网络换成了分组卷积。
对于 b 模块,其运算量为
$$
hw(11cm)/g+hw(33m) + hw(11mc)/g=hw(2cm/g+9m)
$$
而 ResNeXt 运算量为
$$
hw(2cm+9m^{2}/g)
$$
网络结构
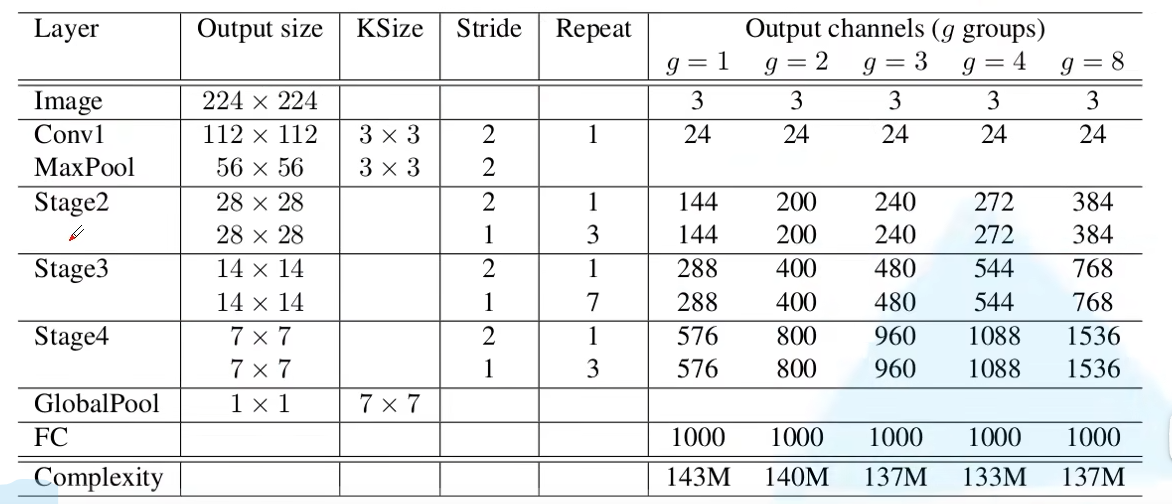
- 对于每一个 stage 中的第一个使用的是 stride=2 的 block
- 对于下一个 stage, 其通道会翻倍
- 在一个 unit 中, 第一个分组卷积与第二个 DW 卷积的输出通道数为当前 stage 输出通道卷的 1/4
- 在 stage 2 中, 第一个
1*1卷积不使用分组卷积.
ShuffleNet v2
衡量模型的指标
FLOPs: 是衡量模型复杂度的一个间接的指标。speed,模型推理的快慢才是一个直接的指标。
对于模型推理速度的影响因素
memory access cost:内存访问的快慢degree of parallelism:并行等级:并行度高的模型会比并行度低的模型快platform:不同的平台上花费的时间也不一样。
优秀的模型设计准则
当卷积层的输入特征矩阵与输出特征矩阵 channel 相等时 MAC 最小(保持 FLOPs 不变时)
$$
MAC >= 2\sqrt{hwB}+\frac{B}{hw},B=hwc_{1}c_{2}(FLOPs)
$$
经过实验的验证,是正确的
重点:
- FLOPs 不变的情况下!
当分组卷积时,组数增大时(FLOPs 不变时),MAC 也会增大
$$
MAC=hw(c_{1}+c_{2})+\frac{c_{1}c_{2}}{g}=hwc_{1}+\frac{Bg}{c_{1}}+\frac{B}{hw},B=hwc_{1}c_{2}/g(FLOPs)
$$
网络设计的碎片化程度越高,速度越慢
可以将碎片化程度理解为分支的程度。分支可以增加准确率,但是会降低运行的效率。
Element-wise 操作带来的影响是不可忽视的
相关的操作有:
- ReLU 操作
- Tensor 相加的操作
- 卷积时使用到的 Bias
这种操作的 FLOPs 很小,但是 MAC 很大。
总结
- 使用平衡的卷积(输入特征数与输出特征数相等)
- 要注意分组卷积的成本(不能无限增加 group 数)
- 降低网络的碎片程度
- 减少使用的 element-wise operations
改进
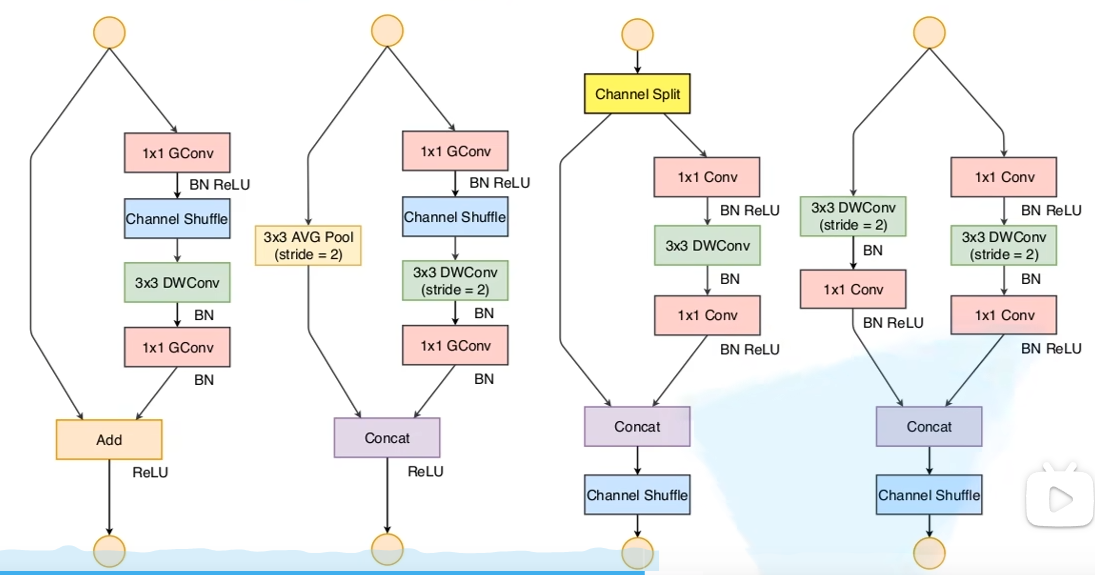
a为 ShuffleNet V 1 且 stride=1 时的情况b为 ShuffleNet V 1 且 stride=2 时的情况c为 ShuffleNet V 2 且 stride=1 时的情况d为 ShuffleNet V 2 且 stride=2 时的情况
关注:
- v 2 中,下面使用的操作是
concat,因为在一开始,将数据分割开了,所以这里要拼接。 Element-wise操作(ReLU,depth-wise)只在一个分支中存在。(V 1 中,合并之后还有一个 ReLU,而 V 2 中,拼接以后就不会使用 ReLU了)- 连续的
Element-wise操作可以合并成一个Element-wise操作,因此可以变相的减少操作。
网络结构
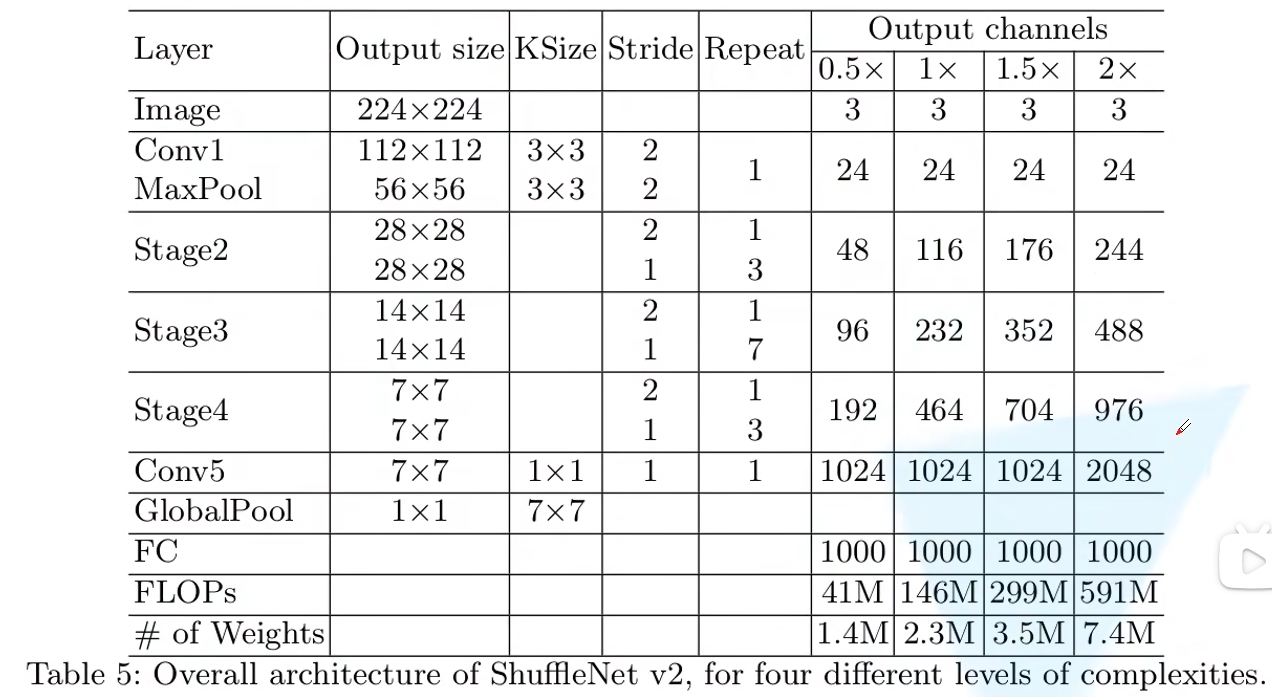
与 v 1 的不同:多了一个 1*1 的卷积层
代码编写
channel_suffle 的实现方法
1 | import torch |
SENet与CBAM
SENet
原理
原理图:
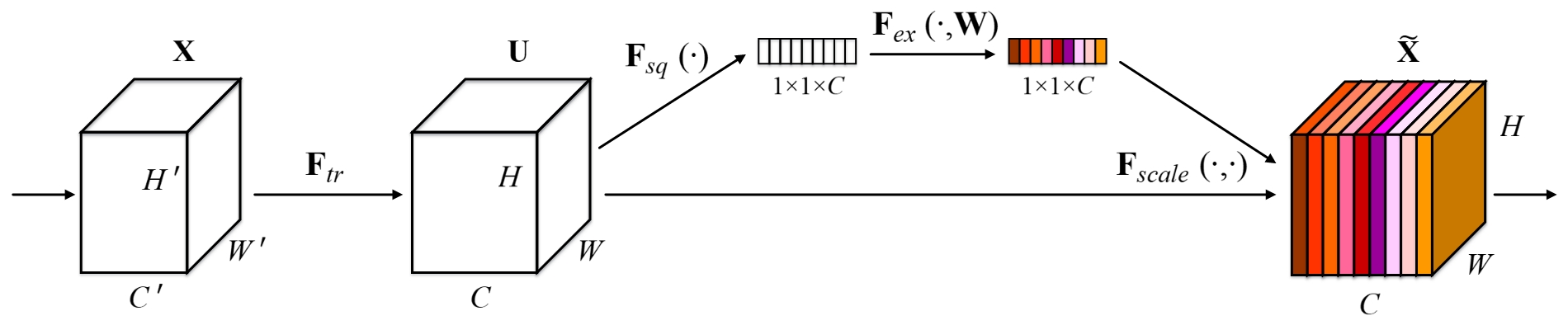
SENet 通过考虑特征通道之间的关系来提升了网络的性能。在该结构中,Squeeze 与 Excitation 是两个关键的动作。其目的是希望显示的建模特征通道之间的相互依赖关系:通过学习的方式(使用了两个全连接层实现)来自动获取到每个特征通道的重要程序,然后依照这个重要程度来提升有用的特征并抑制对当前任务用处不大的特征。
SE 模块的操作如下:
Squeeze: 顺着通道,将一个二维的特征变成一个实数(如果一个特征图的通道数为 n,则处理后,生成一个长度为 n 的向量)(使用平均池化层求平均)Excitation: 为每个特征通道生成权重。(两个全连接层)- 特征重标定:将权重与对应的特征通道上的数值相乘。(先使用
sigmoid函数,并范围约束在0-1之间,然后再相乘)
用途
将 SE 模块应用于残差神经网络
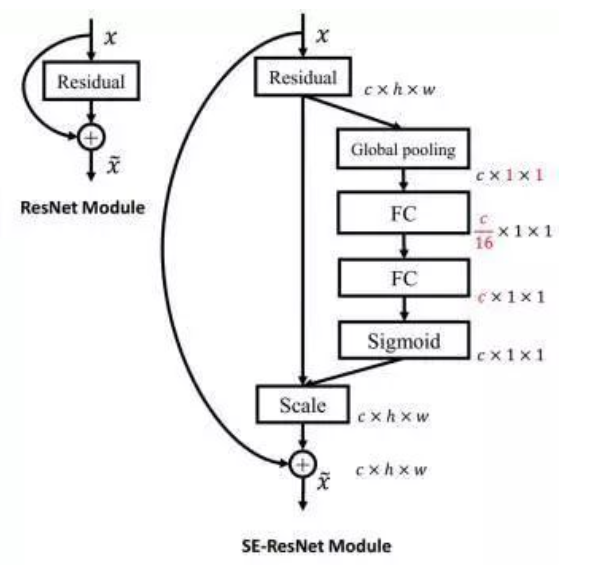
左侧为原始的残差神经网络的结构图,而右侧为应用了 SE 模块的残差神经网络
特点
- SENet 构造非常简单,而且很容易被部署,不需要引入新的函数或者层。除此之外,它还在模型和计算复杂度上具有良好的特性。
- 对模型计算量增加不多,但是可以显著的提高准确率。
- 使用一个数值来描述一个通道的重要程度。
CBAM
是对 SENet 的改进:引入了一个空间注意力模块。
结构图:
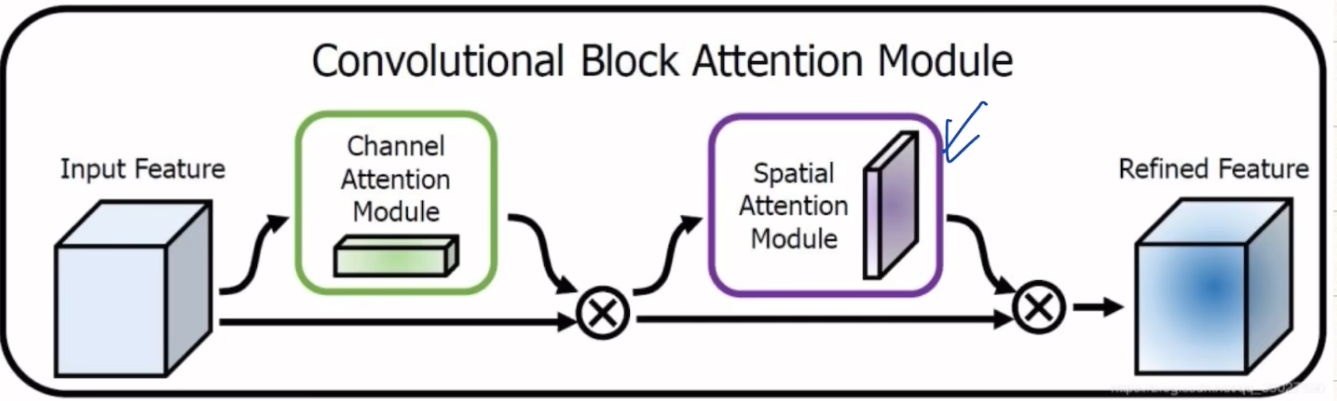
对于一个特征图,先进行通道注意力,再进行空间注意力。进行串行操作,最后得到一个重标定的特征图。
改进
通道注意力模块的改进:
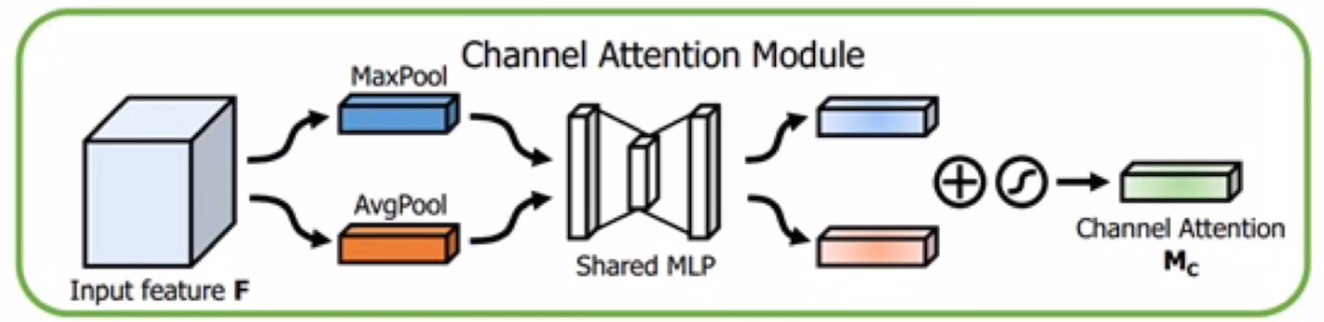
相比对 SENet,对于通道注意力使用了最大池化与平均池化,并且使用了共享的 MLP,将得到的两个权重进行相加,最后才得到输出的通道权重。
- 共享MLP由两层全连接层组成,第一层的输入通道数为C,输出为C/D,第二层输入C/D,输出C。(D为通道减少的倍率)
在代码中,会让MaxPool与AvgPool分别通过MLP来得到对应的结果,再将相加的结果通过sigmoid来得到通道注意力的结果。
空间注意力模块的改进:
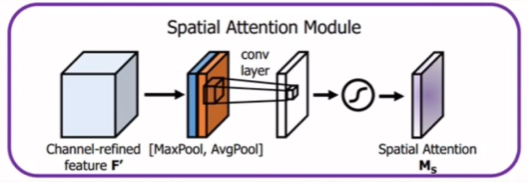
与通道注意力类似,通道注意力是在通道的维度上进行池化,而空间注意力是在空间的维度上进行池化。
- 先使用最大池化与平均池化进行池化操作
- 将结果进行拼接
- 通过一个卷积层来学习空间的相关性
- 使用
sigmoid函数得到空间的注意力。
实验
- 作者经过实验得出:先通过通道注意力,再通过空间注意力,会让网络更加高效。串行的方式会更好
代码
代码来源:csdn
1 | import torch |
代码作业
模型代码
1 | class_num = 16 |
直接根据模型的描述就可以写出以上代码。
运行截图
模型部分:
预测准确度:
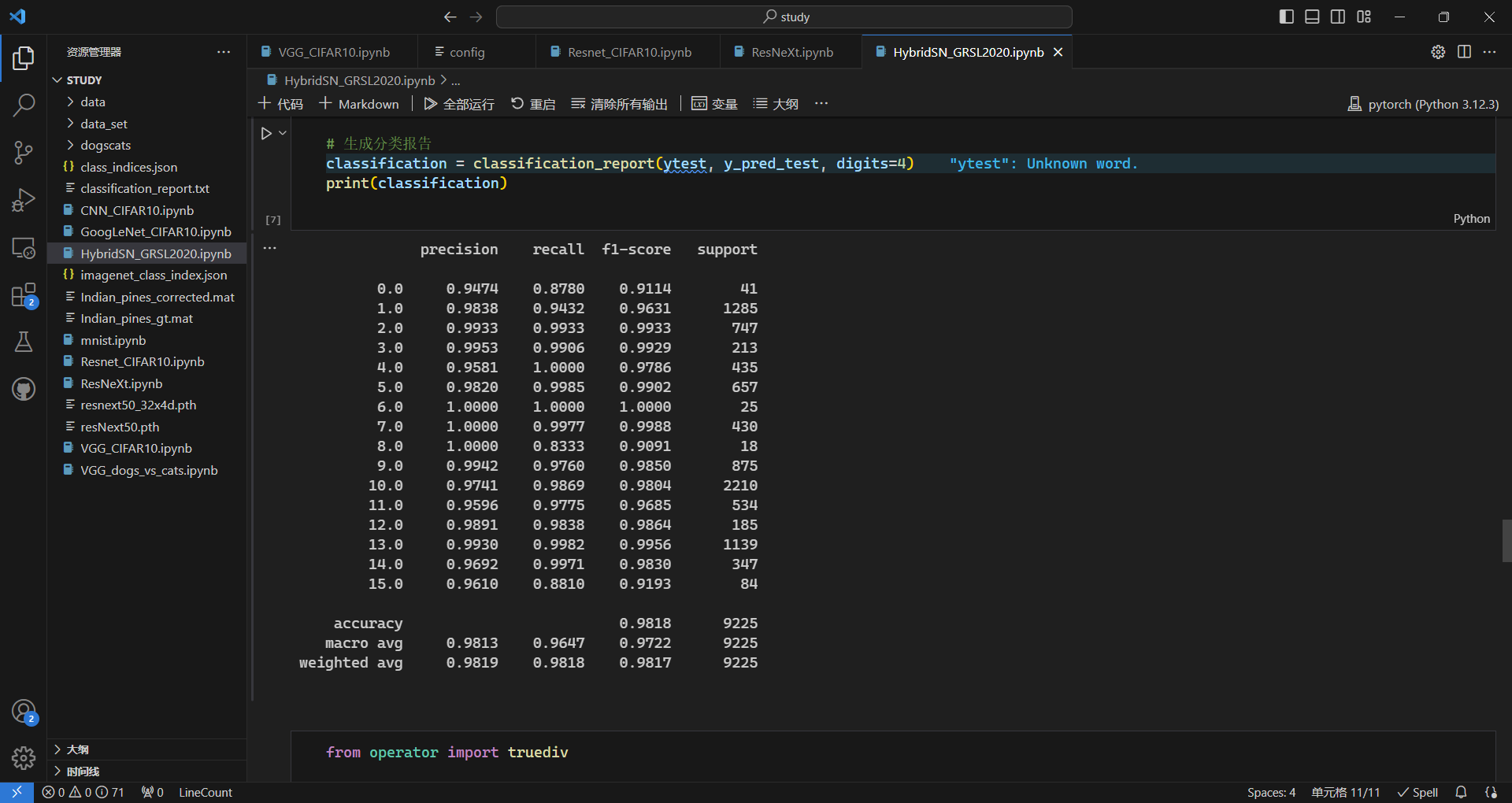
准确度达到了98.18%
预测结果:
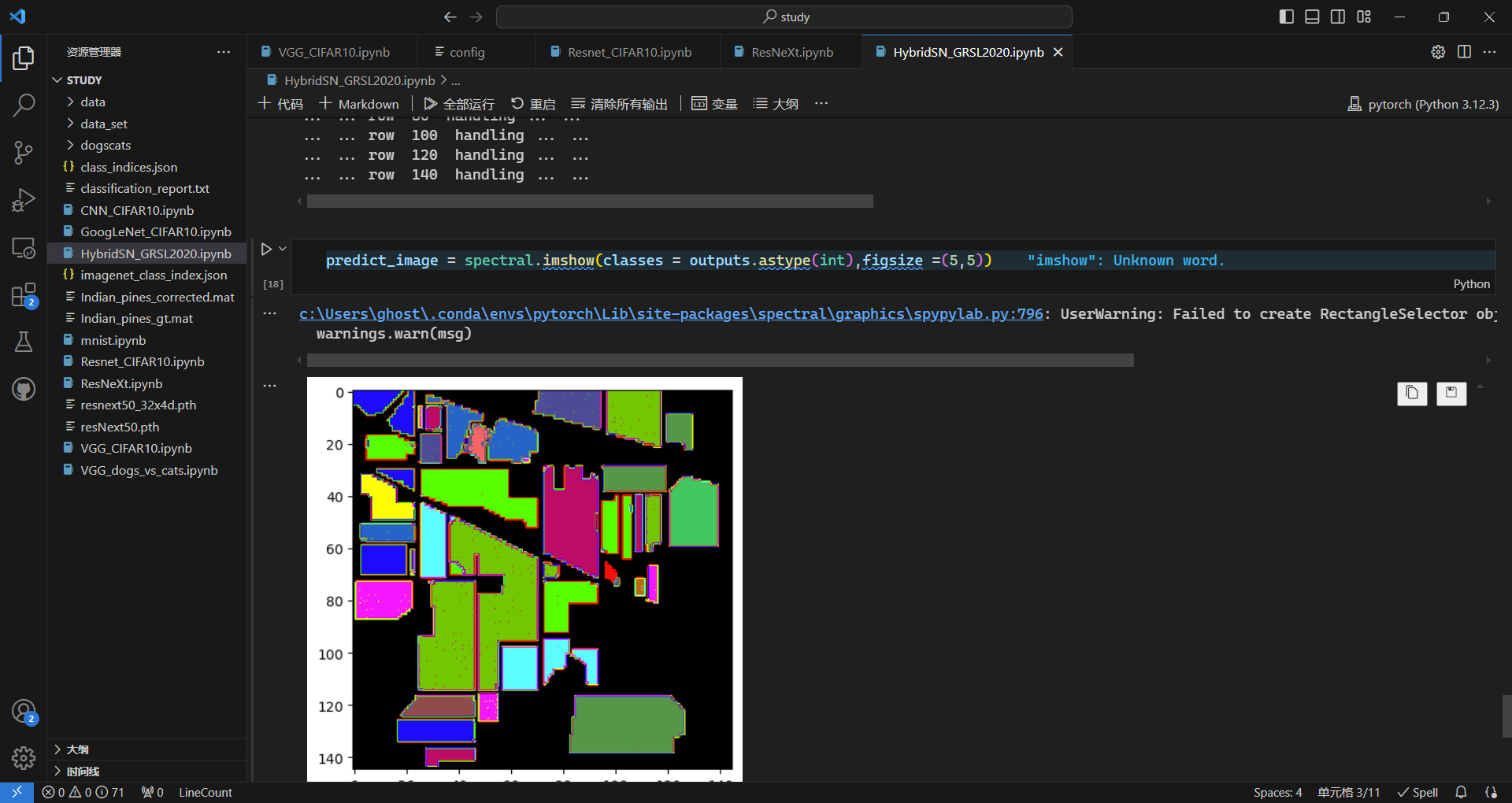
思考题
训练HybridSN,然后多测试几次,会发现每次分类的结果都不一样,请思考为什么?
- 网络中有一个比例为0.4的dropout层,所以网络在每轮训练的时候都会随机的冻结40%的结点,从而使得网络的分类结果不一样
- 网络的训练集为随机的10%的数据,剩下的是测试集,所以每次训练的样本也会不一样,从而使得网络的分类结果不一样
如果想要进一步提升高光谱图像的分类性能,可以如何改进?
从网络的模型中可以看到,整个网络只是使用了最基础的卷积网络线性堆叠而成,因此,对于普通的卷积层,可以使用分组卷积来提高网络的准确度。而对于网络的结构,可以参考ResNeXt模型,通过构建残差块来提高网络精度。还可以参考SENet模型,在每个残差块的后面加上一个SE模块,引入通道注意力机制来进一步的提高网络的准确度。为了网络的运行效率,还可以将使用到sigmoid激活函数的地方换成h-sigmoid激活函数。
depth-wise conv 和 分组卷积有什么区别与联系?
如果输入的通道数为C,输出的通道数为M。则DW卷积可以看成:分成C组的分组卷积。DW卷积将每一个通道都使用一个卷积核进行卷积,而分组卷积是将输入的通道分为了G组,每组有C/G个输入通道,而且,每组会分配M/G个卷积核来做卷积操作。一个组内的参数是共享的,而不同的组是相互独立的。
SENet 的注意力是不是可以加在空间位置上?
可以将其放在空间位置上,CBAM就是对于SENet中SE模块的改进。它将特征图的注意力分为了通道注意力与空间注意力。通过在空间维度上的平均池化与最大池化得到空间位置上的描述中,然后使用卷积层(输入2通道,输出1通道)来生成空间位置上的权重图,最后将权重图与特征图相乘完成特征重标定。
在 ShuffleNet 中,通道的 shuffle 如何用代码实现?
1 | import torch |