Vim-F- Visual State Space Model Benefiting from Learning in the Frequency Domain
论文地址:arxiv
摘要
背景
状态空间模型(SSMs)在语言理解等长序列建模这方面有了显著的进展,而如果要让 SSMs 可以处理图像数据,通常要将 2 D 图像展平为 1 D 序列,这会导致忽略了某些 2 D 局部依赖性。
创新点
使用快速傅里叶变换来获取特征图的频谱,并将其添加到原始特征图中,使 ViM 可以在频率与空间域中建模统一的视觉表示。频率域信息的引入使用 ViM 在扫描的过程中具有全局感受野。
提出了名为 Vim-F 的新模型,该模型采用纯 Mamba 编码器,并在频率与空间域中进行扫描。此外,还将 ViM 中的位置嵌入替换成了分块嵌入(patch embedding),并利用卷积茎(convolutional stem)来获取更多的局部相关性。
正文
背景
ViTs 与 CNNs 相比,通常会有更优越的性能,但是注意力机制在图像大小这方面需要二次复杂,从而会导致在处理下游密集预测任务时计算成本显著增加。
而 SSMs 擅长捕捉长距离依赖关系,同时通过选择性扫描空间状态序列模型(S 6),将先前扫描的信息压缩到隐藏状态中,从而将二次复杂降低到线性。但是由于在处理视觉数据时,要将空间数据展平为一维 tokens,这会导致破坏了局部二维依赖关系。虽然后续对这个缺点有所改进,但是作者认为还没有完全改进好。
创新点
使用二维离散傅里叶亦称将特征图转移为频谱图不会改变它们的形状,频谱图中任意点(x, y)的值 P (x, y) 取决于整个原始特征图。所以频率域扫描确保模型始终具有良好的全局感受野。另一方面,在不考虑频谱偏移的情况下,低频分量位于频谱图的角落,而高频分量位于中心。频谱图的扫描通常在访问低频和高频之间交替,这可以有助于平衡建模。
因此,直接将特征图与其幅度谱相加,然后让 Vision Mamba 编码器学习融合的语义信息。
由于 CNN 固有的空间归纳张文轩,有利于捕捉局部信息,并且 CNN 对数据增强不太敏感,混合架构的训练过程也更稳定,所以,设计了一个 patch embedding:使用多个卷积层进行下采样,然后将特征图展平。采用这种 patch embedding 模块的 Vim-F 被称为 vim-F (H)。最后,Mamba 模型本质上仍是一种循环神经网络,因此 Vim 使用位置嵌入缺乏合理性,但是移除它会显著降低 Vim 的性能。相反,位置嵌入对 Vim-F (H) 的性能影响较小。
贡献
- 提出了 Vim-F,使 SSM 可以在空间与频率域进行扫描,确保 SSM 在扫描过程中始终具有全局视图,从而增强模型解释空间关系的能力。
- 设计了一个新的 patch embedding 模块,该模块利用混合重叠和非重叠的小核卷积进行下采样,然后将特征图展平。
正文
傅里叶变换可以作为隐藏表示的替代混合机制。
预备知识
状态空间模型
状态空间模型通常表示为线性常微分方程。这些模型通过利用一个不可直接观测的可学习的潜在状态 $h(t)$,将输入的 $D$ 维序列 $x(t)$ 转移为输出序列 $y(t)$。映射过程可以表示为:
$$
h’(t)=Ah(t)+Bx(t)
$$
$$
y(t)=Ch(t)
$$
离散化
离散化的主要目标是将常微分方程转移为离散函数,使模型可以与输入信号的采样频率对齐,从而更高效地计算,连接参数(A, B)可以通过零阶保持规则在给定的采样时间尺度 $\Delta t$ 下离散化:
$$
\begin{aligned}
\bar{A} &= e^{\Delta A}, \
\bar{B} &= (\Delta A)^{-1}(e^{\Delta A} - I)\Delta B, \
\bar{C} &= C, \
h(t) &= \bar{A}h(t-1) + \bar{B}x(t), \
y(t) &= \bar{C}h(t).
\end{aligned}
$$
而 $h(t) = \bar{A}h(t-1) + \bar{B}x(t)$ 方程可以被以下公式通过并行计算的方式加速:
$$
y = x \odot K \quad \text{with} \quad K = (C\bar{B}, C\bar{AB}, \ldots, C\bar{A}^{L-1}\bar{B})
$$
其中 $\odot$ 表示卷积操作。
选择性状态空间模型(S 6)
通过引入选择性状态了空间模型,改进了 SSM 的性能,允许连续参数随输入变化,从而增强跨序列的选择性信息处理,这扩展了选择机制的离散化过程:
$$
\bar{B} = sB(x), \quad \bar{C} = sC(x), \quad \Delta= softplus ( Parameter + sA(x))
$$
其中 $sB(x)$ 和 $sC(x)$ 是将输入 $x$ 投影到 $N$ 维空间的线性函数,而 $sA(x)$ 则将 $D$ 维线性投影扩展到必要的维度。Parameter 表示一个可训练的参数矩阵。Softplus 是一个数学运算,其定义为:
$$
softplus(x)=log(1+e^x)
$$
Vim 概述
Vim 先将二维图像 $X$ 重塑为一系列展平的二维图像块 $X_{p}$,因此,Vim 的有效序列长度为 $n=\frac{hw}{p^2}$。然后,Vim 将 $X_{p}$ 线性投影到大小为 $d$ 的向量,并将其添加到位置嵌入 $E_{pos}$,如下所示:
$$
T_0 = \begin{bmatrix} X_{\text{cls}}; & X^1_pW; & X^2_pW; & \cdots; & X^i_pW; & \cdots; & X^d_pW \end{bmatrix} + E_{\text{pos}}
$$
Vim 使用类标记来表示整个图像块序列,记作:$X_{cls}$。然后 Vim 将标记序列 $T_{l-1}$ 发送到 Vim 编码器的第 $l$ 层,并得到输出 $T_{l}$。最后,Vim 对输出的类标记 $T_{0}^L$ 进行归一化,并将其输入到多层感知器 (MLP)状况以获得最终预测 $p$:
$$ T_l = \text{Vim}(T_{l-1}) + T_{l-1} $$
$$ f = \text{Norm}(T^0_L) $$
$$ p = \text{MLP}(f) $$
频域中的二维扫描
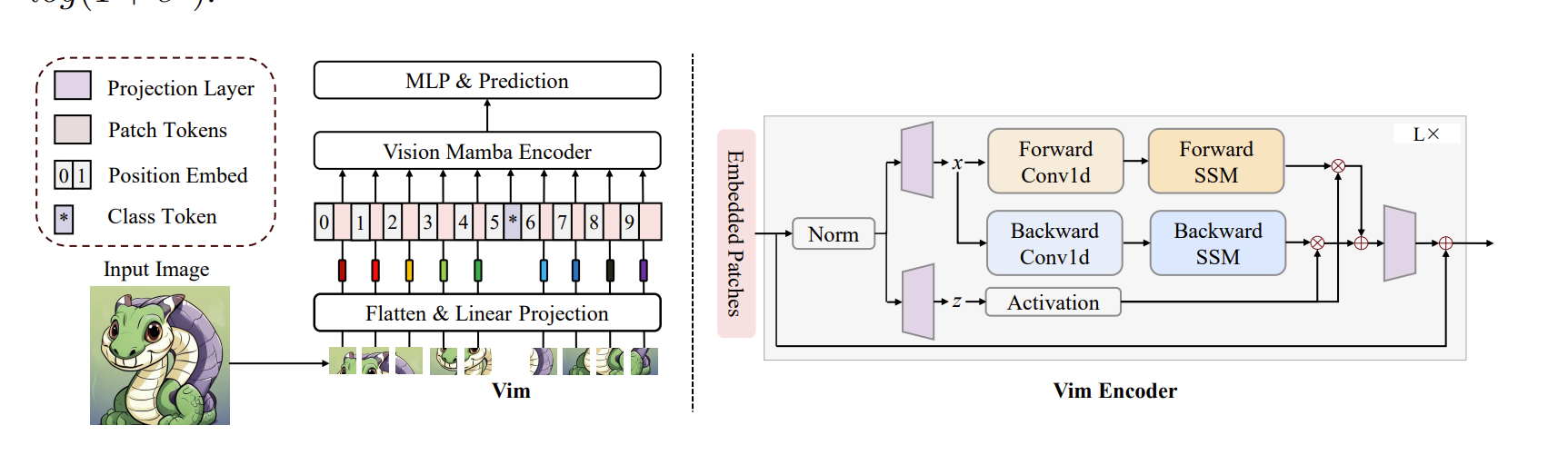
从以上图中可以看到 Vim 中使用的展平方法破坏了这些局部依赖关系,并显著增加了垂直相邻标记之间的距离。
为了解决以上问题,可以通过引入频域扫描来解决这一限制。首先对特征图进行傅里叶变换以获得:
$$
F(u, v) = \sum_{x=0}^{M-1} \sum_{y=0}^{N-1} f(x, y) e^{-j 2 \pi \left( \frac{ux}{M} + \frac{vy}{N} \right)}
$$
其中,$j$ 表示虚数单位,$H$ 与 $W$ 分别表示特征图的高度与宽度。$f(x,y)$ 表示特征图中坐标 $(x, y)$ 处的对应值,$F(u,v)$ 表示频域中坐标 $(u,v)$ 处的对应值。$|F(u,v)|$ 表示 $F(u,v)$ 的模,也称为振幅谱。
此外,傅里叶变换具有平移不变性。所以,这一特性对于解决垂直相邻标记之间距离增加的问题非常有意义,在频域中扫描有助于减少由扫描策略引入的归纳偏差。
因此,频域扫描不需要复杂的策略,并且可以与 Vim 原始的空间域扫描策略一致。最后,使用两个可训练参数作为特征图和对应频谱图的叠加系数,以动态调整空间和频域中的信息强度。Mamba 编码器在空间和频域中建立了视觉信息的统一表示。
补丁嵌入
补丁嵌入的架构如下所示:
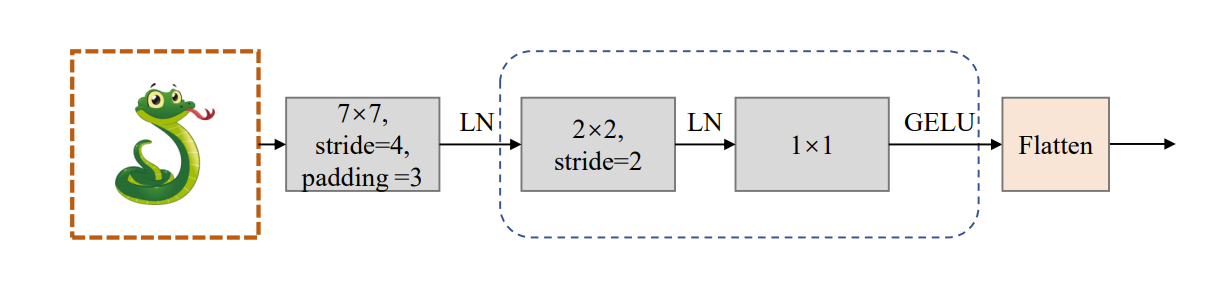
卷积茎(Convolutional stem)
在 Vim 和 ViTs 中,补丁策略通常涉及使用大卷积核进行非重叠卷积。然而,VMamba 中采用了核大小为 4 的非重叠卷积,这表明当前的 ViMs 在补丁设计方面没有进行太多的针对性的设计。而作者认为,非重叠卷积具有较少的归纳偏差,而 Transformer 架构的自注意力机制在建模补丁之间的关系这方面表现出色。因此,采用非重叠卷积可以提升 Transformer 的性能。相反,重叠卷积引入的补丁之间的额外相关性对 ViMs 的扫描机制是有利的。
由上可知:Vim 采用的双向水平扫描策略使得水平和垂直方向上相邻的标记(tokens)在序列中相距较远。此外,标记之间缺乏数据相关性使得模型难以理解垂直方向上的空间关系。引入可训练的位置嵌入可以明确地为模型提供平面空间中每个标记的绝对位置,从而缓解上述问题。
具体的过程:首先利用一个步幅为 4 的 7×7 卷积层来建模输入图像的局部相关性。然后,通过两个下采样块对特征图进行两次下采样。每个下采样块由一个步幅为 2 的 2×2 卷积层和一个 1×1 卷积层组成。
效率分析
Vim-F 需要执行二维 DFT,增加了计算复杂度,但由于使用 Cooley-Tukey FFT 算法,这部分复杂度可以忽略。补丁嵌入的卷积干在 Vim-F (H) 中包括更多卷积层,但计算成本增加不显著。与 LocalVim 相比,Vim-F (H) 在性能和效率之间实现了更好的平衡。
模型评估
图像分类
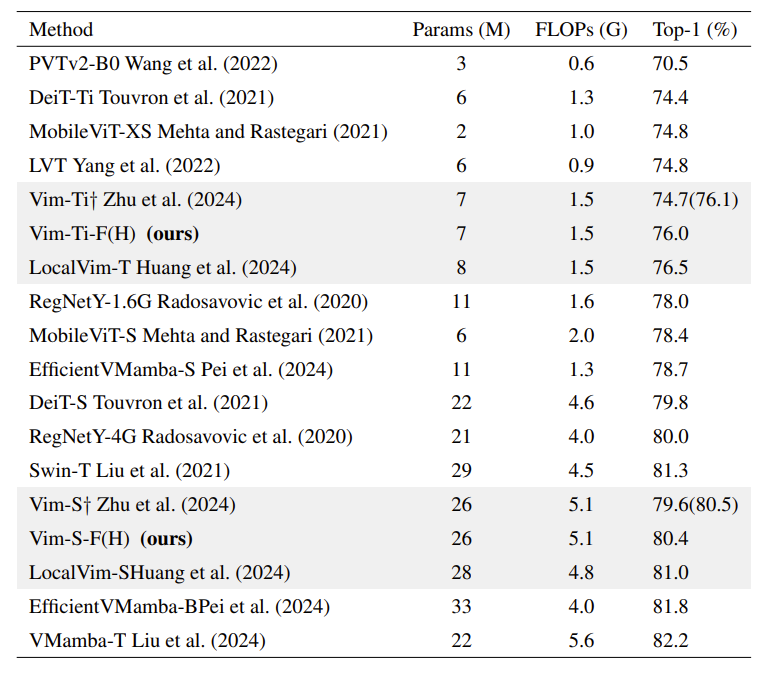
在 ImageNet-1K 上训练模型并在其验证集上评估性能。其实验结果如下所示:
目标检测和实例分割
使用 Mask-RCNN 作为检测器,在 MSCOCO 2017 数据集上评估。
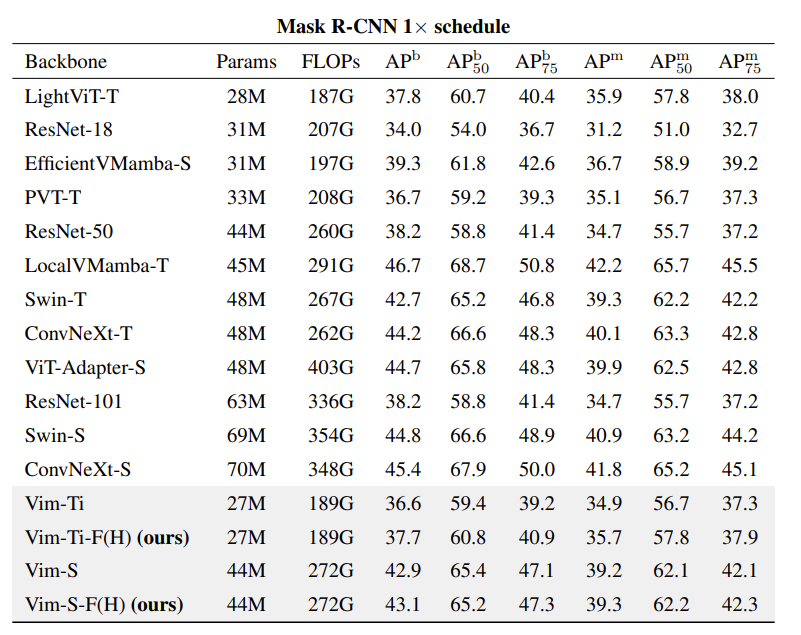
Vim-F 始终优于 Vim,同时在参数数量与计算成本之间也有良好的平衡。
消融实验
频域扫描的效果
将位置嵌入移除后,性能会下降。然而,频域扫描带来的全局感受野降低了模型对位置嵌入的依赖,从而使 Vim-Ti-F 的性能下降幅度较小。

卷积词干(convolutional stem)的影响
将 Vim-Ti 中的传统补丁嵌入替换为论文提出的卷积干预进一步提高性能。如上图所示。