Multi-Scale VMamba- Hierarchy in Hierarchy Visual State Space Model
论文地址:arxiv
摘要
背景
ViTs (视觉变换器)在各种视觉任务中有显著的成就,但是它们受限于二次复杂度,而 SSMs (状态空间模型)因其全局感受野和相对于输入长度的线性复杂度而引起了广泛关注。
问题
为了提高 SSMs 在视觉任务中的性能,因此采用了多扫描策略。可是这种方法有显著的冗余。
解决
经过研究发现:长程依赖性是关键的因素,所以引入了MSVMamba模型:在原始和下采样的特征图上采用多尺度二维扫描技术,以学习长程依赖性并减少计算成本。同时集成了卷积前馈网络(ConvFFN)来解决通道混合的问题。
创新点
- 本篇论文将 VMamba 框架中的 VSS 模块替换为多尺度状态空间(MS 3)模块,从而提高了其性能。
正文
前提介绍
SSMs:这是一种用于表示连续系统的数学模型。它将输入序列 $x(t)$ 映射到一个潜在空间表示 $h(t)$,然后基于这个潜在表示来预测输出序列 $y(t)$。公式如下:
$$
h’(t) = Ah(t) + Bx(t), y(t) = Ch(t)
$$
其中,$A,B,C$ 都是可以学习的参数。
为了在深度学习框架中使用 SSMs,需要将其从连续时间域转换到离散时间域。通过引入时间尺度参数 $\Delta t$ 并使用零阶保持(ZOH)方法进行离散化,可以得到离散化的状态空间模型:
$$
h(t)=Ah(t-1)+Bx(t),y(t)=Ch(t)
$$
其中,$A,B$ 为离散化后的参数。
离散化后的状态空间模型可以通过全局卷积的方式实现输出预测:
$$
y=x*K
$$
$K$ 为卷积核,包含了一系列矩阵乘积。
选择性状态空间模型(S 6)通过使参数 $B$、 $C$ 和 $\Delta t$ 依赖于输入,进一步提升了模型的性能。这样,卷积核 $K$ 会根据输入动态变化,从而增强模型的灵活性和适应性。
多扫描策略的分析
使用 S 6 块处理图像数据时,二维特征图 $Z$ 会被展平为一维序列 $X$,其中每个元素代表一个图像标记。而由于模型货币于优先考虑最近标记的信息,当序列长度的增加,远处标记的贡献会显著减小。此外,S 6 块的因果属性意味着信息只能单向传播,阻止了早期标记访问后续标记的信息。这与图像的非因果性质不匹配,导致直接应用 S 6 块处理视觉任务效果不佳。
为了解决以上问题,提出了不同方向上扫描图像特征并整合这些特征的方法。使用多扫描策略,可以获得更丰富的特征表示,从而提升模型的性能。
多扫描策略通过最小化标记之间的有效距离,缓解了长距离遗忘问题。具体来说,对于任意两个标记,策略会采用多条扫描路径,每条路径可能改变它们的相对位置,从而减少它们之间的最小距离。这种方法减少了远距离标记之间影响的衰减,增强了模型保持和利用长距离信息的能力。
VMamba 中多扫描策略的成功是因为:它能缓解图像数据中的非因果特性(即数据之间没有直接因果关系)和减轻长距离遗忘问题(即随着时间推移,系统可能会忘记远距离的信息)。缺点:随着扫描路径数量的增加,计算成本也会线性上升,从而引入计算冗余。
多尺度二维扫描
随着扫描距离的增加,tokens 的贡献会逐渐衰减,这被称为长距离遗忘问题。为了解决这个问题,减少 tokens 的数量是一种有效的方法。同时,由于 S 6 块的计算复杂度与 tokens 的数量线性相关,因此减少 tokens 的数量不仅能缓解长距离遗忘问题,还能提高计算效率。
基于以上考虑,引入了多尺度二维扫描(MS2D)。先通过应用具有不同步幅的深度卷积(DW 卷积)生成不同尺度的层次特征图。然后这些多尺度特征图在 VMamba 中通过四条不同的扫描路径处理。使用步幅为 1 的 DW 卷积生成高分辨率的特征图 $Z_{1}$,使用步幅为 s 的 DW 卷积,生成低分辨率的特征图 $Z_{2}$。之后将这两个特征图分别通过 S 6 块处理,生成处理后的序列 $Y_{1},Y_{2},Y_{3}, Y_{4}$。得到该序列后再将其转换回二维特征图,对于使用降采样的特征图,则使用插值进行合并。最终生成通过 MS2D 增强的特征图 $Z’$
其中使用到的公式有:
- 计算 $Y_{1},Y_{2},Y_{3}, Y_{4}$
$$
Y_{1} = S6(\sigma_{1}(Z_{1}))
$$
$$
[Y_{2},Y_{3},Y_{4}]=S6([\sigma_{2}(Z_{2}), \sigma_{3}(Z_{3}),\sigma_{4}(Z_{4})])
$$
$\sigma$ 是将二维特征图转换为SS2D中使用的一维序列的变换, $Y$ 是处理后的序列。 - 合并成一个二维特征图
$$
Z’{i}=\gamma{i}(Y_{i}),i={1,2,3,4}
$$
$$
Z’=Z’{1}+Interpolate(X(Z’{j})),j={2,3,4}
$$
其中 $\gamma$ 是 $\sigma$ 的逆变换,$Z’$ 是通过MS2D增强的特征图。
使用下采样操作,可以将序列的长度减少 $s^{2}$ 倍,这也可以将标记间的距离缩短 $s^{2}$ 倍,从而缓解远距离遗忘的问题。MS2D 与 SS2D 的区别是,将总序列的长度从 4L 减少到 (1 + 3/S^{2})L。
模型架构
本篇论文将 VMamba 框架中的 VSS 模块替换为多尺度状态空间(MS 3)模块,从而提高了其性能。
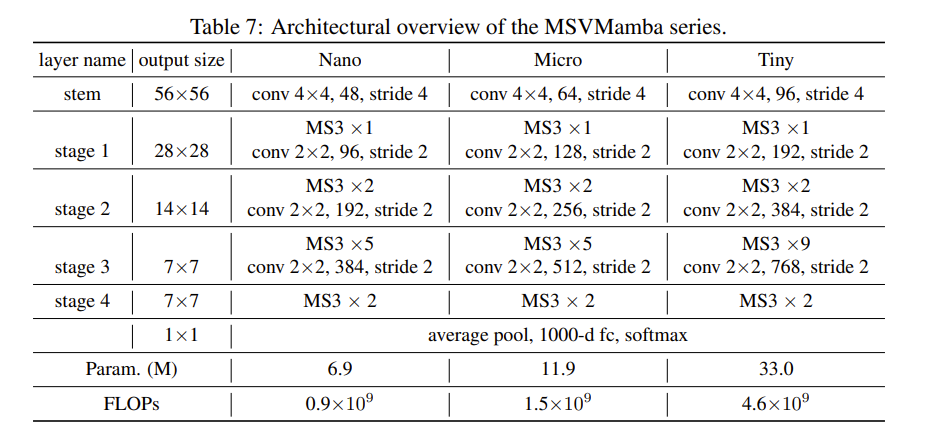
以下是本文创新点:MS 3 模块的结构图。
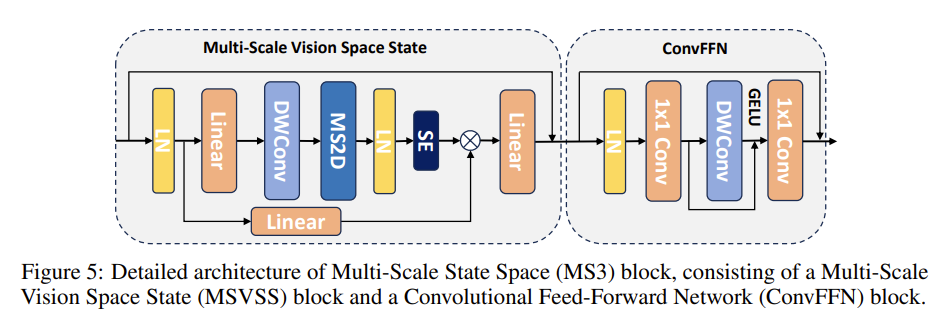
MS 3 模块
MS 3 模块包括一个多尺度视觉状态空间(MSVSS)组件和一个卷积前馈网络(ConvFFN)。MSVSS 组件通过改造 VMamba 中的视觉状态空间框架,将 SS 2 D 替换为 MS 2 D,从而在单层中引入层次设计。此外,在多尺度 2 D 扫描之后集成了一个 Squeeze-Excitation(SE)模块。
ConvFFN 模块
ConvFFN 由一个深度卷积和两个全连接层组成,作为通道混合器。可以以增强不同通道之间的信息流动,符合视觉 Transformer 的结构范式。
性能分析
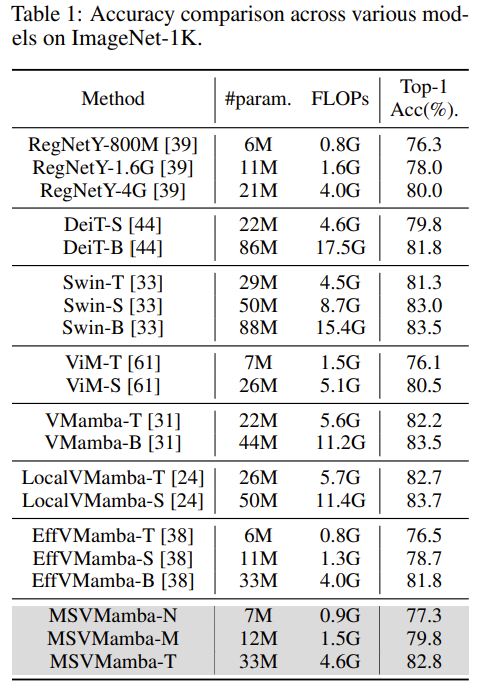
图像分类
在 ImageNet-1k 数据集上,得到以下的性能:
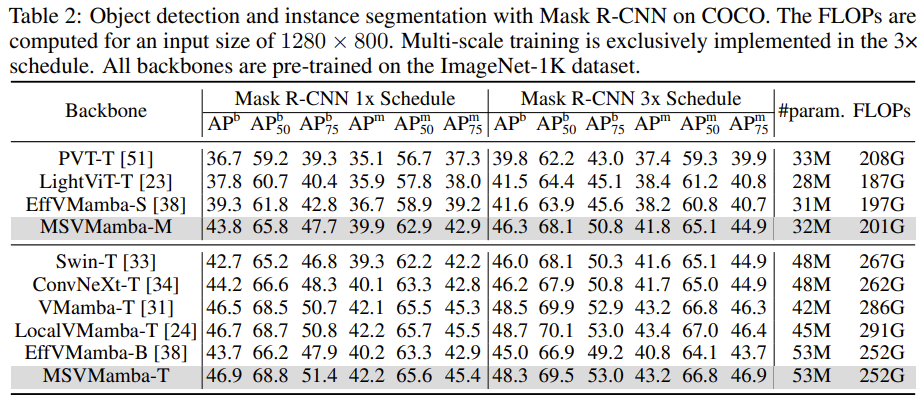
物体检测
在 MSCOCO 数据集上完成。
语义分割
在 ADE20K 数据集上完成的测试
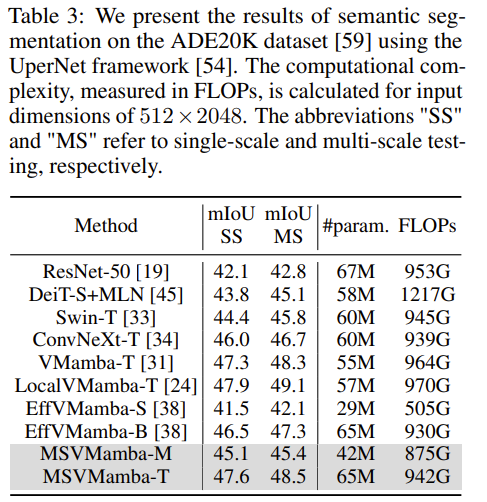
消融研究
MS2D 的有效性
在多尺度 2 D 扫描上。将 VMamba 中的 SS2D 替换为我们的 MS2D,同时保持大致相等的 FLOP 计数,准确率从 69.6%提高到 71.9%。
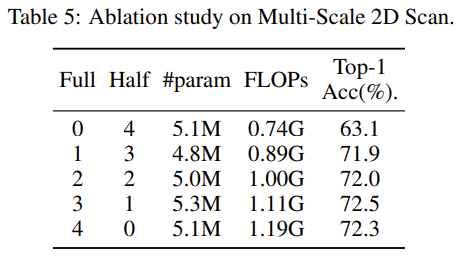
扫描次数的研究
该研究考虑到了考虑了全分辨率和半分辨率分支。将所有扫描放在半分辨率分支中导致了细粒度特征的显著丢失,导致模型准确率大幅下降。将两次或三次扫描放在全分辨率分支中,相较于仅一次扫描,分别提高了 0.1%和 0.6%的准确率,但引入了大约 12%和 25%的额外计算成本。将四次扫描分配给全分辨率分支,实际上恢复到 SS 2 D 方法,计算成本增加了 34%,而准确率仅提高了 0.4%。
SE 模块的有效性
通过加入 SE 模块,将准确率提高了 0.5%,而额外的计算成本很小。
ConvFFN
通过引入 ConvFFN(卷积前馈网络)作为通道混合器,显著提高了通道间的信息交互能力。实验结果显示,这一调整使模型准确率提高了 2.0%。
模型的缺点
增加模型的规模(即增加模型的参数数量)也可以缓解长程遗忘问题。如果通过增加模型规模就能解决这个问题,那么多尺度设计带来的改进可能只是边际的,效果并不显著。
知识点
长程衰减
长程衰减(Long-range decay)指的是在处理序列数据(如文本或图像块序列)时,随着距离的增加,信息的传递和整合能力逐渐减弱的现象。这种衰减会导致模型在捕捉和利用远距离依赖关系时变得困难。
在单扫描策略中,图像数据沿一个固定方向处理。如果在这个方向上,远距离信息逐渐减弱(即长程衰减),那么模型在处理远距离依赖时会有困难;多扫描策略通过在多个方向上扫描图像数据来缓解长程衰减的问题。例如,除了从左到右扫描外,还可以从右到左、从上到下、从下到上等多个方向进行扫描。这样,即使在一个方向上出现了长程衰减,其他方向可能不会受到同样的影响,信息可以通过这些方向进行补偿,从而在整体上减轻长程衰减的影响。
通道混合器
主要目的是增强不同通道之间的信息流动,从而提高模型的表达能力和性能。主要的功能:
- 信息整合
- 特征重校准
- 提升模型性能
- 结构优化
常见的混合器有:
- SE 模块:对原始通道进行加权
- 深度卷积与逐点卷积:DW 卷积对每个通道单独进行卷积操作,而逐点卷积则对所有通道进行
1*1卷积,从而实现通道之间的信息混合。 - ConvFFN:通过深度卷积与全连接层的组合,实现了通道混合的功能。