Temporal Attention Unit- Towards Efficient Spatiotemporal Predictive Learning
论文地址:arxiv
摘要
作者提出了一个时空预测学习的能用框架,其中空间编码器与解码器捕捉帧内特征,而中间的时间模块捕捉帧间关联。
同时,为了并行化时间模块,作者提出了时间注意单元(Temporal Attention Unit, TAU),它将时间注意力分解为帧内静态注意力与帧间动态注意力。
作者还引入了一种新的差分散度正则化(differential divergence regularization)来考虑帧间变化。
正文
作者通过对当前主流的时空预测模型的抽象,得出了以下的框架:
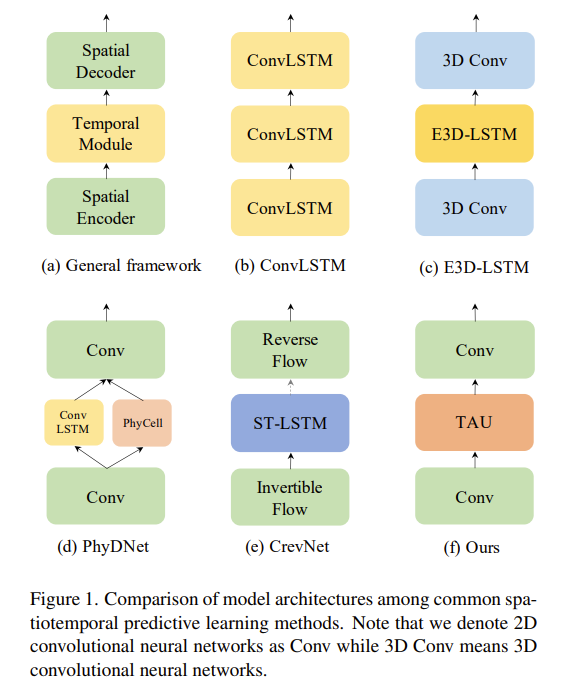
基于这个框架,作者认为时间模块在时空预测学习中起着至关重要的作用。
作者提出了叫做”时间注意单元”的新型可并行化注意模块来捕捉时间演变。将时间注意分解为帧内静态注意与帧间动态注意。
此外,作者认为均方误差损失仅关注帧内差异,提出了一种差分散度正则化(differential divergence regularization),也关注帧间变化。
问题的定义
时空预测学习问题为:
给家一个视频序列,其中包含时间 $t$ 的过去 $T$ 帧。而模型的目标是预测从时间 $t+1$ 开始的后续 $T_0$ 帧。其中预测的帧为一张具有通道数 $C$,高度 $H$,与宽度 $W$ 的图像。在实验中,将视频序列表示为张量,即 $X^{t,T} \in R^{TCHW}$ 与 $Y^{t+1, T’} \in R^{T’CHW}$。
具有可学习参数 $\Theta$ 的模型通过探索空间和时间依赖关系来学习一个映射 $F_\Theta: X^{t,T} -> Y^{t+1,T’}$。在本论文中,$F_\Theta$ 是一个神经网络模型,通过最小化预测的未来帧和真实未来帧之间的差异来进行训练,最优参数 $\Theta ^*$ 为:
$$
\Theta^* = \arg \min_{\Theta} L(F_{\Theta}(X^{t,T}), Y^{t+1,T_0})
$$
模型概览
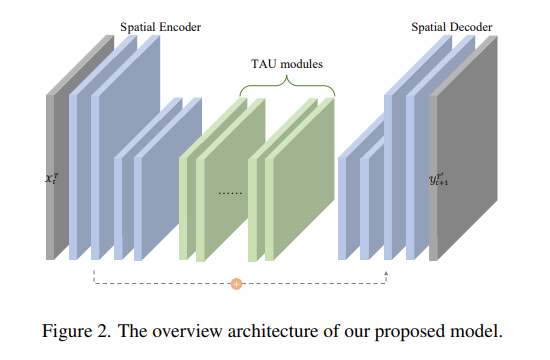
该模型为输入数据 Moving MNIST 的模型概览。空间编码器由四个普通的 2 D 卷积层组成,空间解码器由四个 2 D 转置卷积层组成。在 pytorch 中,分别为 Conv2D 与 ConvTranspose2d。
作者在第一个卷积层与最后一个转置卷积层之间添加了一个残差连接,以保留空间相关特征。空间编码器与解码器是间是多个 TAU 模块的堆栈,用于提取时间相关特征。
时间注意力单元(TAU)
时间注意力单元的处理过程:
假设输入的视频张量 $B \in R^{BTCHW}$,其中视频数量 $B=|B|$。在空间编码器与解码器中,我们将顺序输入数据 $BTCHW$ 重塑为 $(BT)CHW$,以便只考虑空间相关性。在时间模块中,将特征 $BTCHW$ 重塑为 $B*(T*C)HW$,使帧按顺序排列在通道维度上。
作者将时间注意力分解为帧内静态注意力与帧间动态注意力,如下所示:
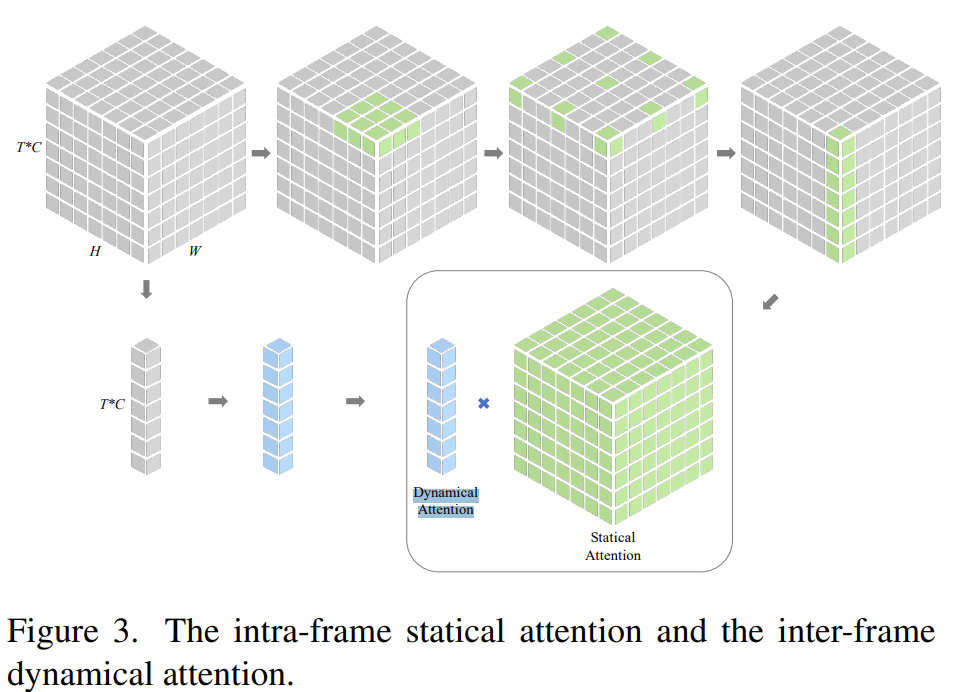
作者使用小核深度卷积(DWConv)与带膨胀的深度卷积(DW-D Conv)和 1*1 卷积来模拟大核卷积。通过在帧内获得的大感受野,静态注意力能够捕捉长距离依赖。同时为了学习沿时间轴学习时间演变,作者以”压缩和激励”的方式学习通道的注意力权重。而最终的注意力为动态注意力与静态注意力的乘积。
以下是 TAU 模块的详细内容:
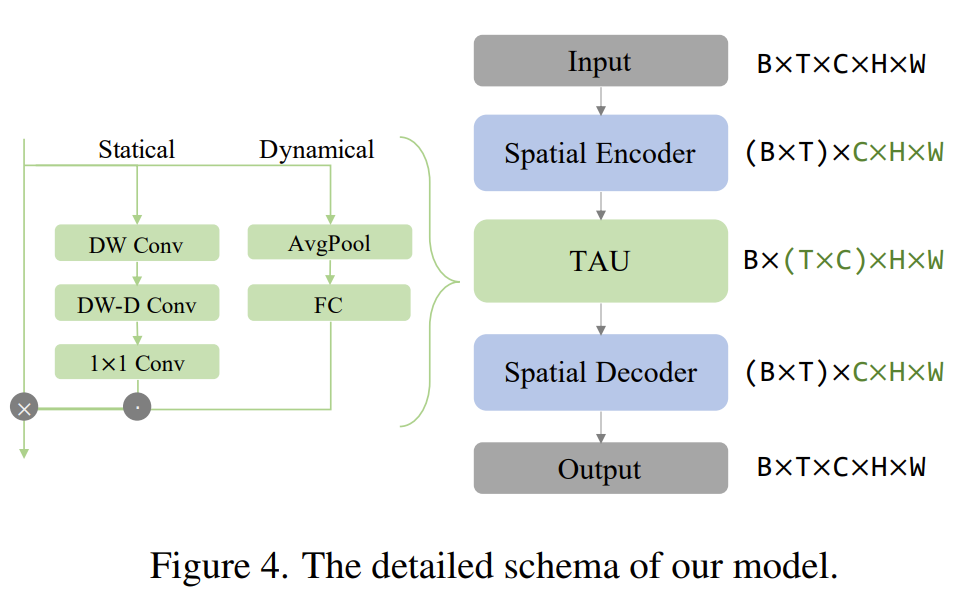
FC 全连接层,AvgPool 为平均池化,$\otimes$ 表示Kronecker积,$\odot$ 表示Hadamard积。
差分散度正则化
该正则化方法可以强迫模型学习连续帧之间的差异并意识到固有的变化。
通过计算预测帧和真实帧之间的差异,并使用 softmax 函数将其转换为概率分布,然后使用 Kullback-Leibler 散度来惩罚高差异帧,从而提高模型对帧间变化的敏感度。
模型以完全无监督的方式进行端到端的训练,整体的目标函数由均方误差损失与加权常数 $\alpha$ 的差分散度正则化组成:
$$
L = \sum_{i=1}^{T’} \left| \hat{Y} - Y \right|^2 + \alpha L_{\text{reg}}(\hat{Y}, Y)
$$
模型评估
作者从以下三个方面来验证
- 标准时空预测学习
- 跨不同数据集的泛化能力
- 预测具有灵活长度的帧
使用的数据集:
- Moving MNIST
- TaxiBJ
- KTH
- Caltech Pedestrian
以下是详细信息:
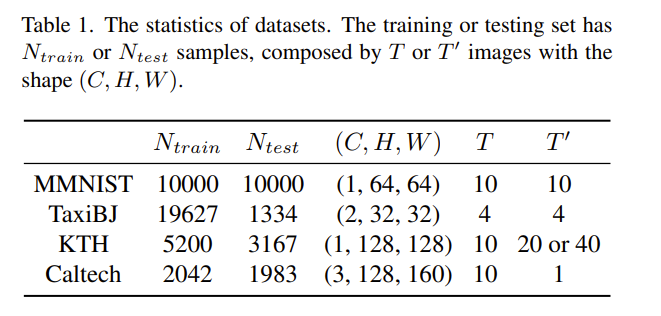
训练样本数 $N_{train}$,测试样本数 $N_{test}$。
测量方法:
均方误差(MSE)、平均绝对误差(MAE)、结构相似性指数(SSIM)和峰值信噪比(PSNR)来评估预测质量。MSE和MAE估计绝对像素误差,SSIM测量空间邻域内结构信息的相似性,PSNR是信号最大可能功率与失真噪声功率之间的比率。
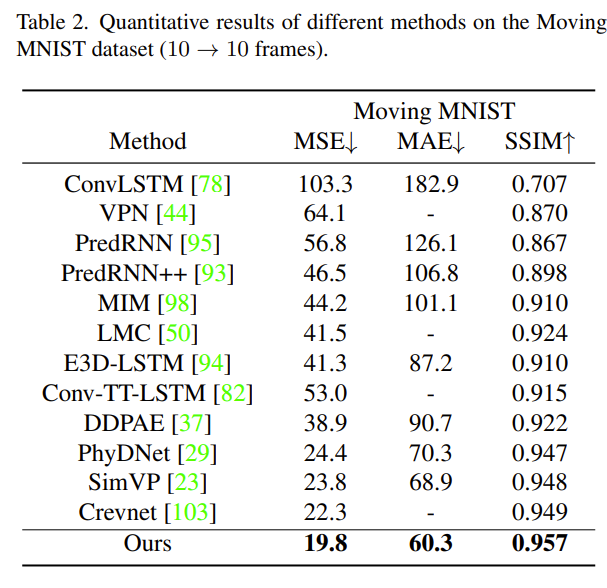
在 Moving MNIST 数据集上的效果如下:
在 TaxiBJ 数据集上的效果如下所示:

在不同数据集上的泛化能力如下所示:
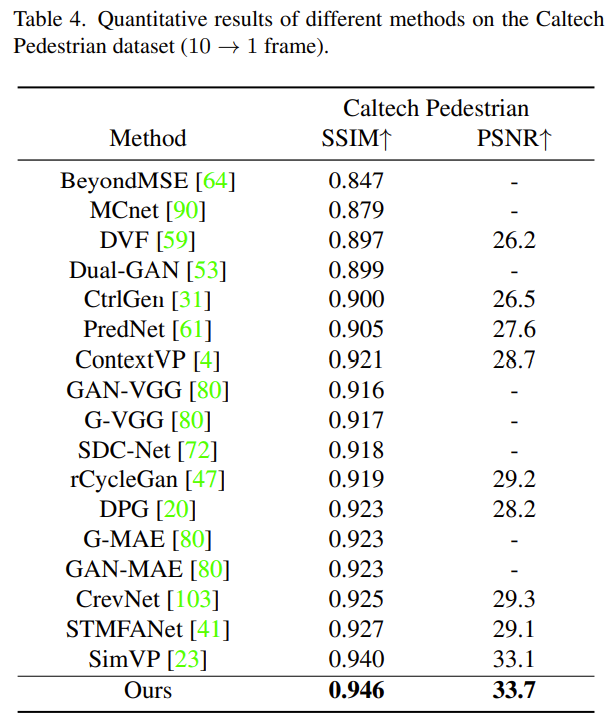
预测灵活长度的帧
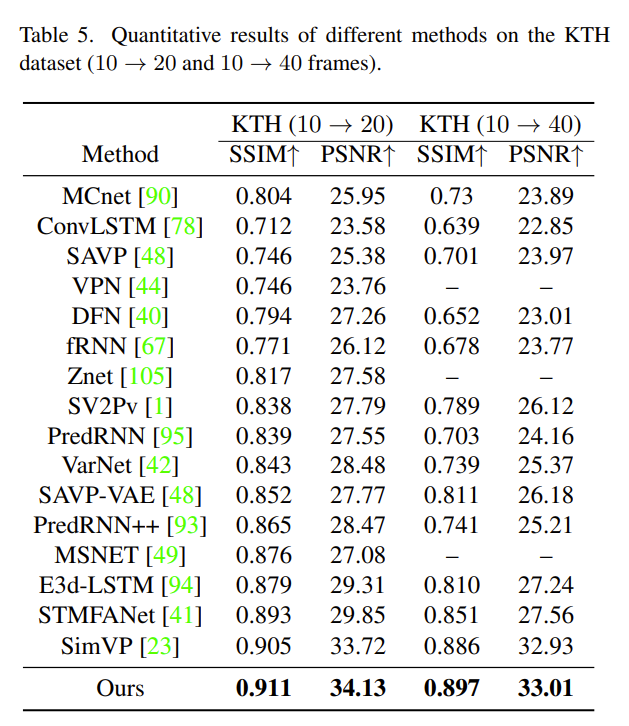
使用峰值信噪比(PSNR)和结构相似性指数(SSIM)作为评估指标,从感知角度衡量逐帧预测质量。以下是结果分析表:
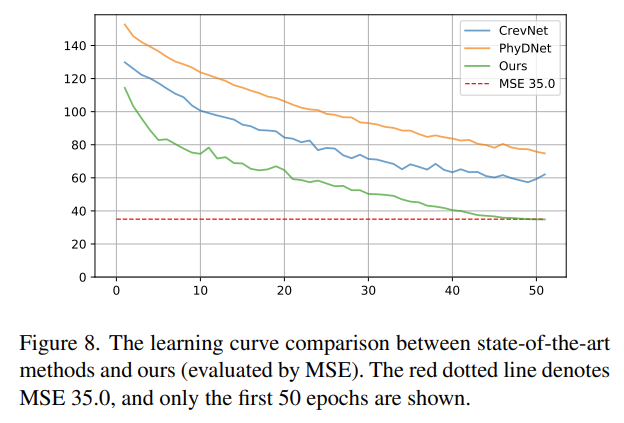
训练时间
TAU 是可并行计算架构,所以可以快速的收敛与高训练速度。以下是不同的模型的收敛速度对比:
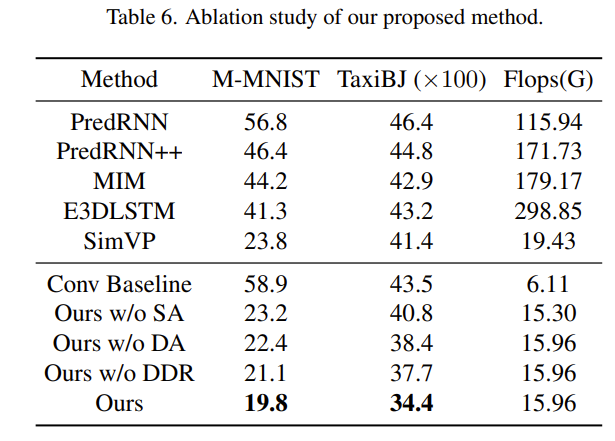
消融实验
通过消融研究,证明了 TAU 模块和微分散度正则化对模型的性能很重要。
如果使用普通的卷积块替换了 TAU,则会显著降低性能。不使用微分散度正则化时,也会削弱预测结果。同时,TAU 的静态注意力(SA)与动态注意力(DA)也发挥了很重要的作用。