Efficient Visual State Space Model for Image Deblurring
项目地址:arxiv
摘要
背景
CNNs 与 ViTs 在图像修复中的任务表现很出色,并且 ViTs 通常比 CNNs 表现要好,因为它们可以够捕捉到图像中的长距离依赖关系和输入依赖特性。
问题
ViTs 的计算复杂度随着图像分辨率的增加而呈现二次增长。因此,在处理高分辨率图像时,ViTs 的计算开销很大。
解决
提出了 EVSSM 用于图像的去模糊,利用了状态空间模型(SSMs)对视觉数据的优势。
创新
开发了一种高效的视觉扫描模块,该模块在每个基于 SSM 的模块之前应用各种几何变换,捕捉有用的非局部信息并保持高效性。
正文
背景
卷积网络的局限性:其在空间上是平移不变和局部的,不能有效地建模全局和空间变异信息,这限制了其在图像恢复中取得更好效果的能力。
Transformer 中的自注意机制的局限性:自注意机制(即缩放点积注意力)在处理高分辨率图像时,涉及到关于令牌数量的平方空间和时间复杂度,这变得难以接受。尽管已经有优化效率的方法了,但是这些方法会牺牲了最终的质量。同时,还仍然难以有效地表征长距离依赖关系和非局部信息。
状态空间模型(SSMs)的优点:可以在线性时间复杂度下建模长距离依赖。改进的 SSM,比如 Mamba,其缺点有:会将图像展平为 1 D,这会破坏空间结构,无法捕捉到局部信息。此外,如果将 SSMs 应用于视觉任务,通常采用了多方向扫描的方法,这会增加计算成本。
创新点
- 只在一个方向上扫描图像特征
- 在每次扫描前,使用简单的任何亦称来调整图像,可以更高效的捕捉到有用的信息,同时还可以保持计算成本的最低增加。
贡献点
- 提出了简单而高效的视觉状态空间模型 EVSSM,可以高效地恢复高质量图像
- 开发了一种有效且高效的扫描策略,可捕捉非局部空间信息
正文
EVSSM 总体架构
该模型基于层次化的编码器-解码器框架。
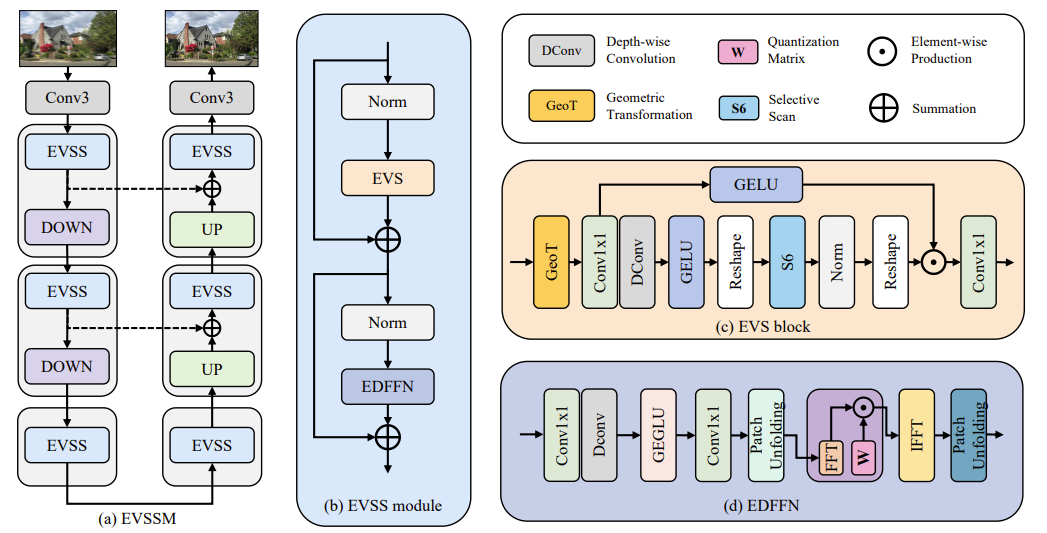
- 通过
3*3的卷积层提取浅层特征 - 浅层特征被输入到一个具有 3 层对称的编码器-解码器网络中。每层的编码器和解码器由若干高效视觉状态空间(EVSS)模块组成
- 在每一层中,输入特征通过 EVSS 模块逐步处理,生成中间特征。通过双线性插值和 1×1 卷积实现上采样和下采样,并在编码器和解码器之间添加跳跃连接。
- 通过一个 3 × 3 的卷积层生成残差图像。
- 复原图像通过将残差图像与原始模糊图像相加获得。
- 模型通过最小化一个包含图像像素差异和傅里叶变换域差异的损失函数进行训练,权重参数 $\gamma$ 设定为 0.1。
状态空间模型
状态空间模型可以使用一组一阶差分或微分方程来表示:
$$
h’(t)=Ah(t)+Bx(t),\ y(t)=Ch(t)+Dx(t)
$$
输入信号为 $x(t)$,隐藏状态为 $h(t)$,输出响应为 $y(t)$。$A,B,C,D$ 为可学习的权重矩阵。
状态方程可以使用零阶保持(ZOH)技术离散化:
$$
h_{t}=\bar{A}h_{t-1} +\bar{B}x_{t}, \ y(t)=Ch_{t}+Dx_{t},
$$
$$
\bar{A} = e^{\Delta A},\bar{B}=(\Delta A)^{-1}(e^{\Delta A}-I) \cdot \Delta B.
$$
因此,Mamba 提出了选择性扫描 (s 6)机制,以同时实现输入依赖的权重和线性计算复杂度。当其运用在视觉任务时,有显著的挑战:视觉数据本质上是非顺序的,并且包含局部纹理和全局结构等空间信息。此外,S 6 是一个递归过程,在处理当前时间步 ?? T 的输入时,它只能利用前面时间步的信息,而不能考虑未来时间步的信息。
EVS 块
该块只会在一个方向上扫描,并在每次扫描前对输入进行一次任何变换(翻转和转置)。由于卷积的平移不变性,几何变换不会影响卷积本身,而只会影响选择性扫描的过程。
在本篇论文中,如果 EVS 块在整个网络的第 i 个 EVSS 中,则会对输入 $F_{in}$ 进行以下处理:
$$
\left{\begin{align*} Transpose(F_{in}) \ if i % 2 = 0, \ Flip(F_{in}) \ if i % 2 = 1.\end{align*}\right.
$$
通过以步公式可以发现,图像特征将在每 4 个 EVSS 模块后自动恢复到原始空间结构。如果 EVSS 模块总数不能被 4 整除,则会通过逆变换来恢复原始空间结构。
可以将选择性扫描进行公式化,其公式如下:
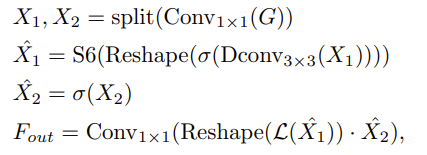
其中,$Conv_{1*1}()$ 是一个卷积核大小为 1*1 的卷积。DConv_{3*3}() 是一个卷积核大小为 3 的 DW 卷积。$L$ 为归一化层。split() 表示在通道维度上分割图像特征。$\sigma$ 表示 GeLU 激活函数。S 6 表示选择性扫描机制。
EDFFN
其主要目的是提高从 EVSS 模块提取特征的效率和效果。FFN 是深度学习模型中的关键部分,负责重建清晰的潜在图像。
EDFFN 会在 FFN 网络的最后阶段进行频域筛选,从而来降低计算复杂度。
模型评估
Realword 数据集

HIDE 数据集上

GoPro 数据集
效果最好

其他数据集
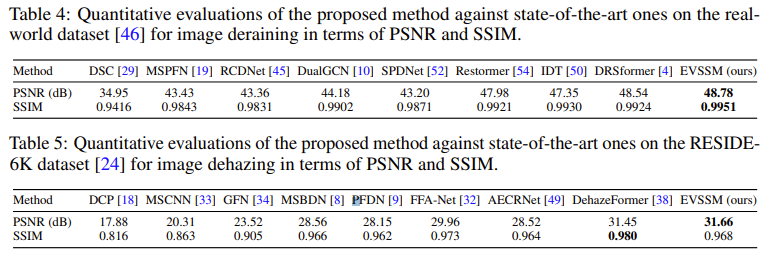
评估去雨和去雾任务中的图像恢复效果
消融实验
EVS 的有效性
移除任何变换(单向扫描)后发现 PSNR 低了 0.14 dB。使用双向扫描或四向扫描,可以发现虽然可以缓解状态空间模型在处理视觉数据时的限制,但是会导致网络参数数量和计算复杂度的增加,双向扫描增加了 38%的时间,四向扫描增加了 105%的时间。
几何变换的有效性
分别去掉了翻转变换(简称 w/o F)、转置变换(简称 w/o T)以及同时去掉翻转和转置变换(简称 w/o F&T)后,其结果如下

结果表明,应用翻转或转置变换可以取得更好的效果,将 PSNR 提高至少 0.04 dB。同时,还不会显著增加计算成本或运行时间。