Transformer学习笔记
部分图片来源:csdn
Transformer基础
Transformer 一开始用于自然语言处理。RNN,LSTM 都有缺点:
- 记忆的长度比较短
- 无法并行化:必须先计算
t0,再计算t1,…
Transformer 解决了以上的两个问题。
Self-attention
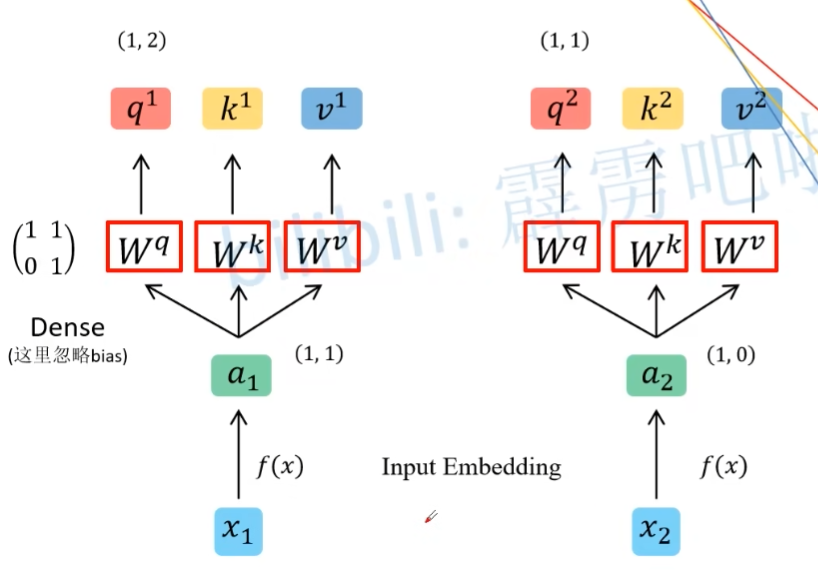
假设输入的是 x1 与 x2,则会通过 Embedding 层,将其映射到一个更低的维度上,得到 a1 与 a2。然后会通过 $W^{q}$,$W^{k}$,$W^{v}$ 矩阵,生成对应的 q, k, v。这里的矩阵是共享的,且全连接层实现,是可以训练的。而 q,k,v 的计算公式如下:
- $q^{i}=a^{i}W^{q}$
- $k^{i}=a^{i}W^{k}$
- $v^{i}=a^{i}W^{v}$
q表示query,用于匹配key,而k表示key,用于被q匹配;v 代表从 a 中提取到的有用的信息。
并行化:可以将不同的 a 拼接在一起,然后再做矩阵乘法:
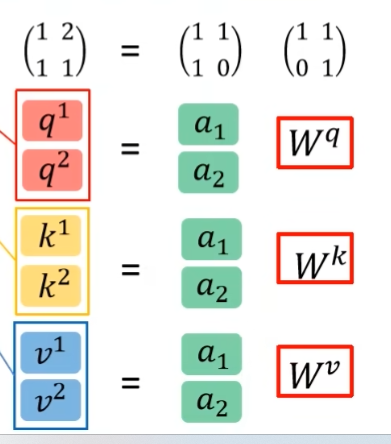
将所有的 q 合并,可以得到一个 Q;同理,可以得到 K,V。
q 与 k 的匹配过程
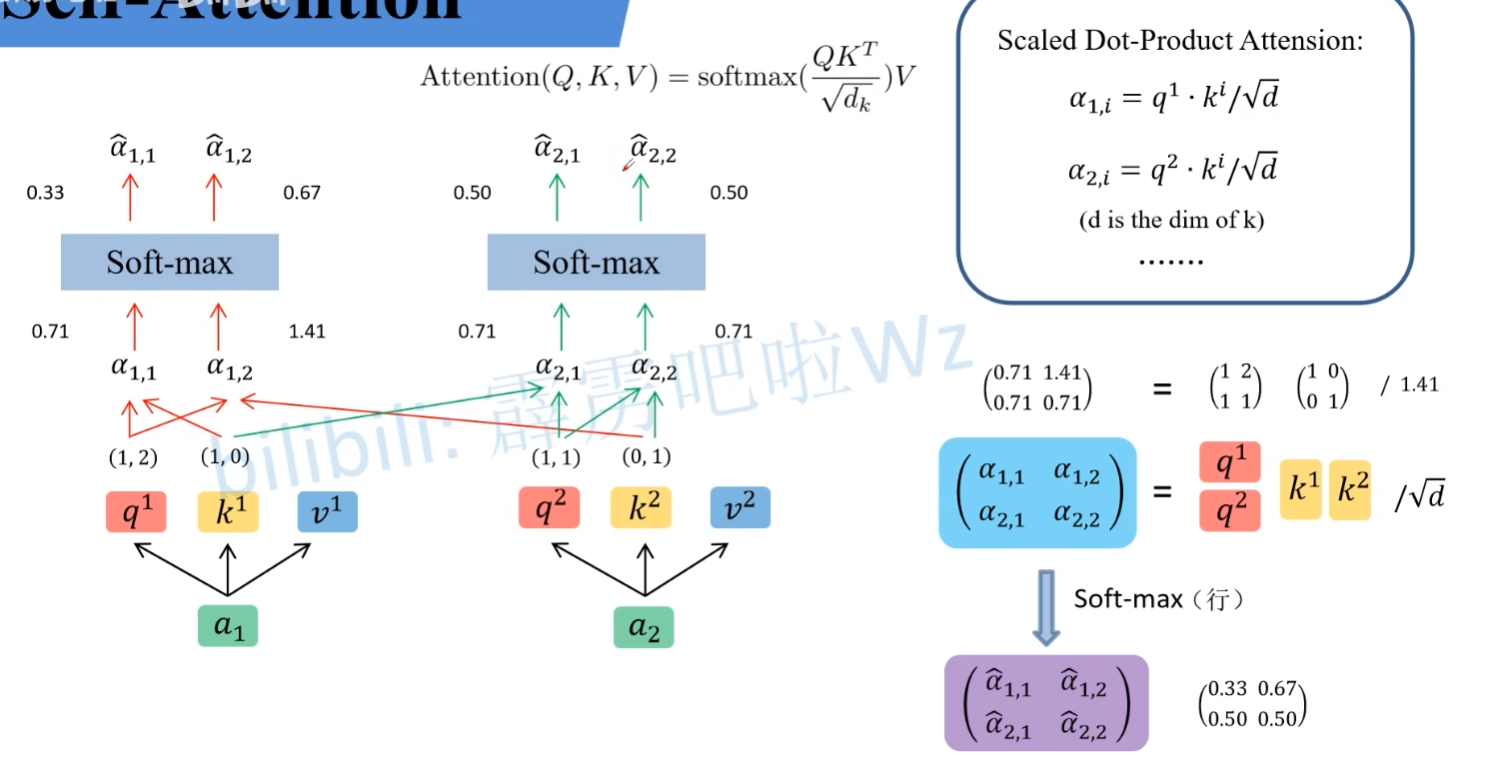
在公式中,d 表示向量中元素的个数。在本例中,向量中有两个元素,则 d 为 2。
$\hat{a_{i,j}}$ 表示某一个 v 的权重,权重越大,那么会越关注某一个 v。而 $\hat{a_{i,j}}$ 的计算也是可以通过矩阵乘法实现了,公式在图的右下角。
得到 $\hat{a_{i,j}}$ 后,可以通过以下公式。得到 bi
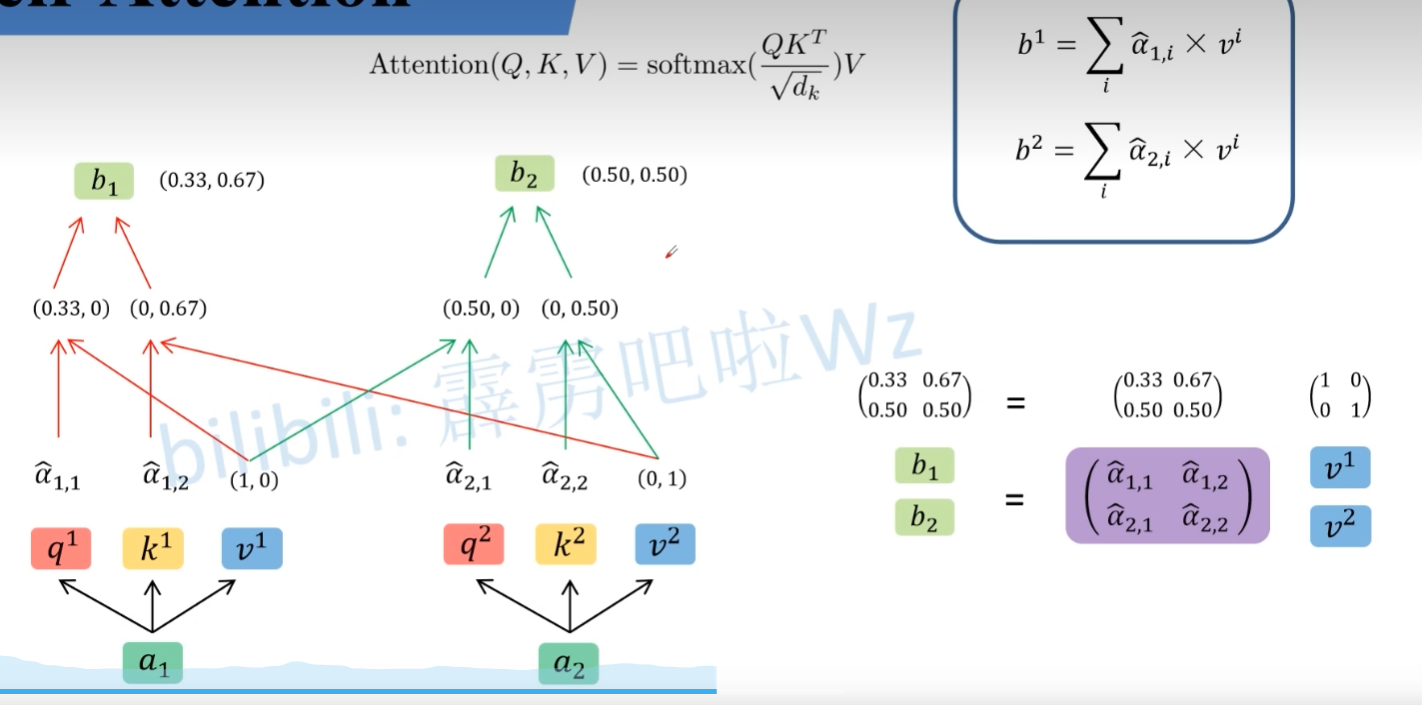
这一步也可以使用矩阵乘法实现。
Multi-head self-attention
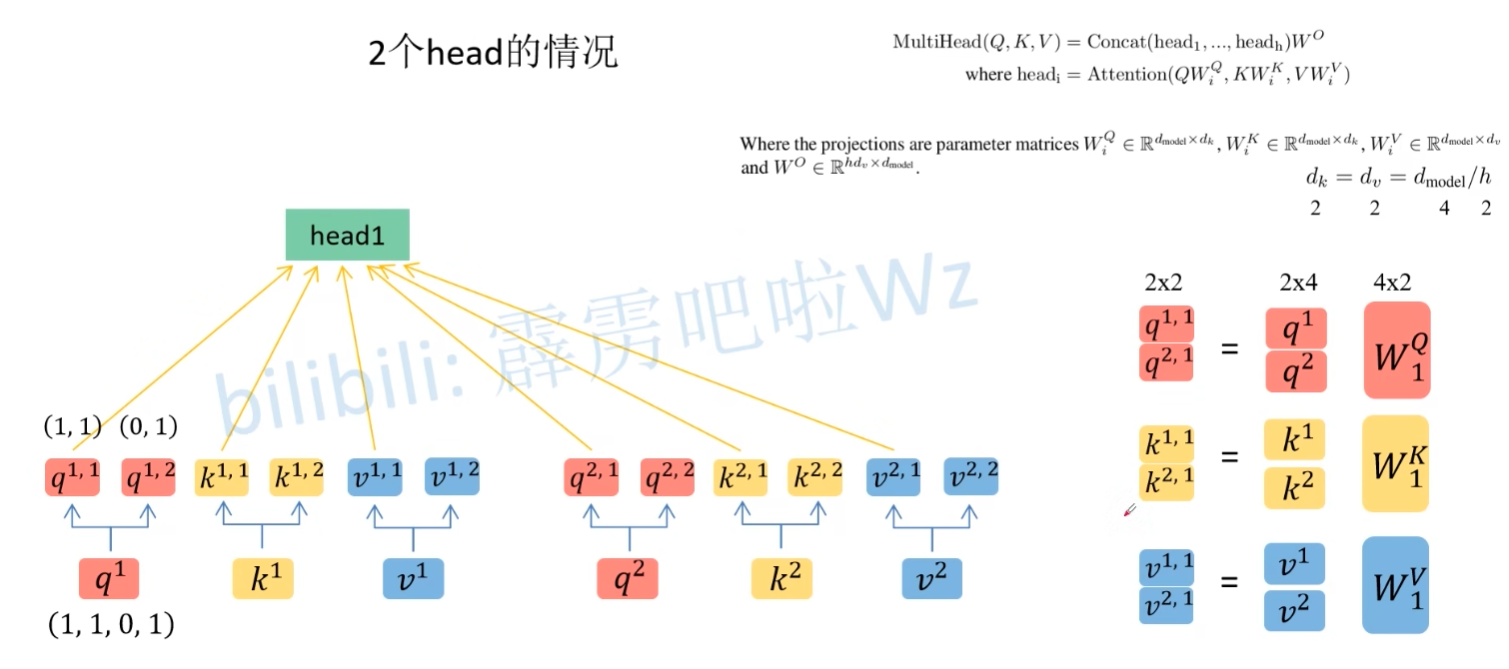
计算过程与 self-attention 差不多,只不过是把 q, k, v 拆分成两组(假设有 2 个 head),然后再分别计算,即可得到两个 head。
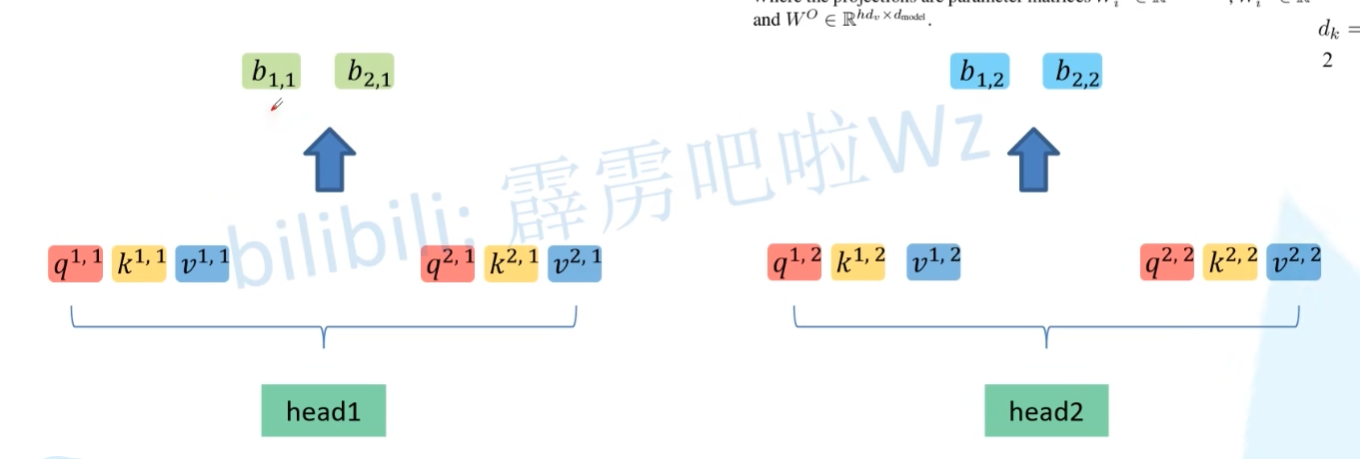
得到两个 head 后,再执行上面说的公式,就可以得到不同的 $b_{i,j}$。

先将 $b_{i,j}$ 以 i 为组进行拼接,然后使用 $W^{O}$ 进行相乘,即可得到 $b_{i}$。
缺点:
如果数据输入的顺序是 a1, a2, a3,则输出的顺序为 b1, b2, b3,此时将 a2 与 a3 更换位置,输出为 b1, b3, b2。可以发现 b1 是不会被影响的。因此,为了解决这个问题,提出了位置编码的思想:在输入的 a 的时候,会加上 $pe_{i}$ 的偏置。其计算有两种方法:
- 根据论文公式计算出位置编码
- 可训练的位置编码
这两个方式都有差不多的效果。
Vision Transformer
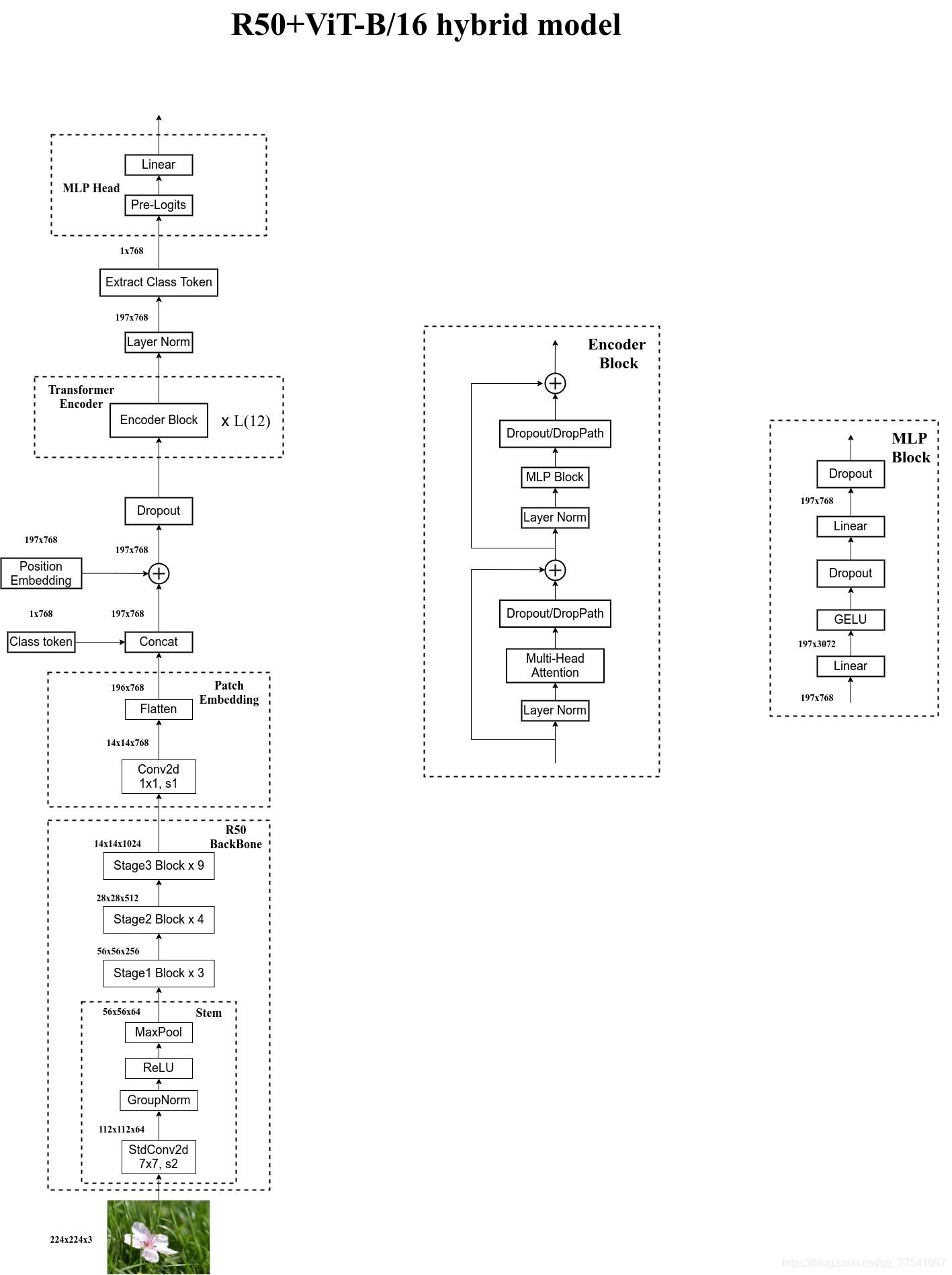
模型架构:
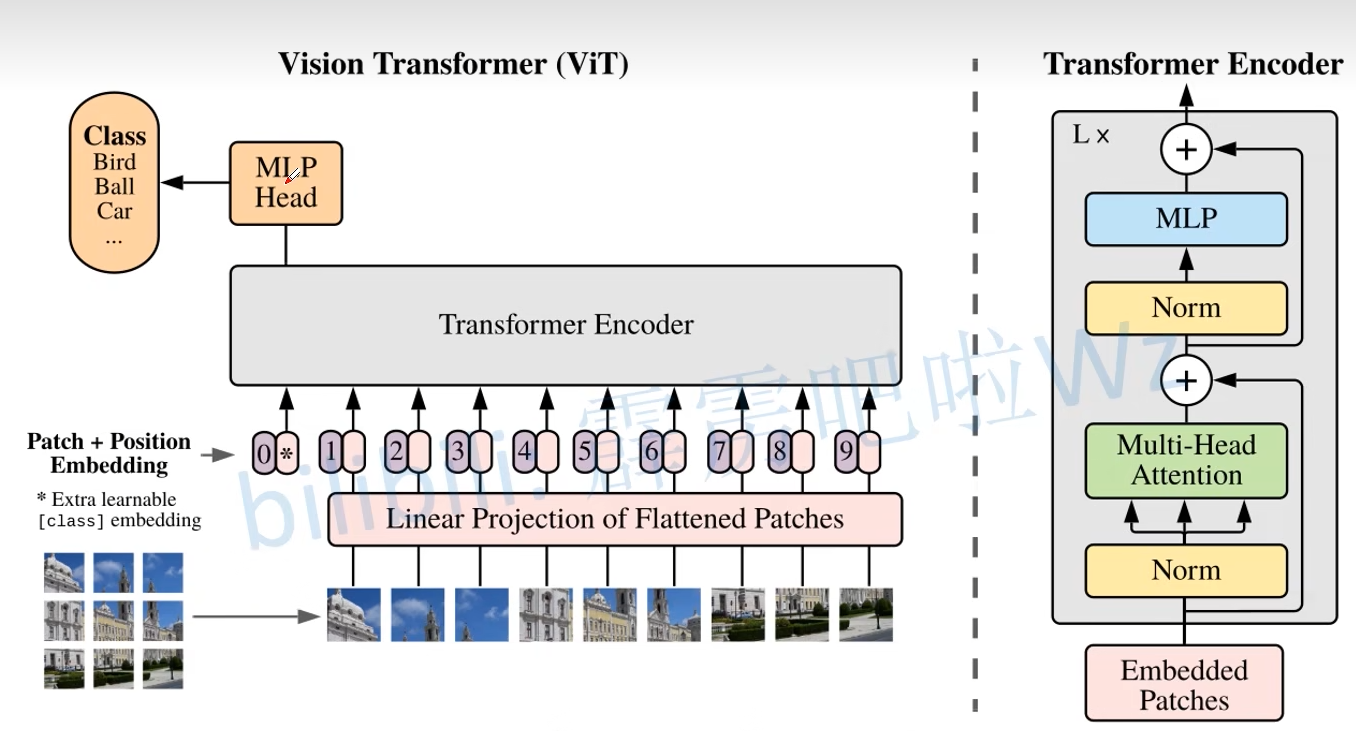
整体流程
在输入一个图像时,会先将图像分成一个一个的小块(patch)。然后将其直接输入 embedding 层。之后会得到每一个 patch 得到的 token。之后还会再加上一个用于分类的 class token,与其他的 token 是相同的。得到 token 以后再加上位置编码,输入到 Encoder 中。之后提取 class token 的输出结果(该模型用于分类)。
Embedding 层
对于标准的 Transformer 模块,要求输入的是 token (向量)序列,即二维矩阵 [num_token, token_dim]。在代码中,可以直接用一个卷积层来实现。比如:viT-B/16,使用的是 16*16,步长 16,卷积核个数为 768 。[224,224,3]->[14,14,768]->[196,768]。再加上 class token cat([1,768], [196,768])->[197,768]。再叠加位置信息:[197, 768]->[197, 768](直接相加,所以没有维度没有变化)
使用位置编码会比不使用位置编码好很多,但是,不同的位置编码的差别不大。
Encoder 层
Encoder 是由多次堆叠以下模块实现的。
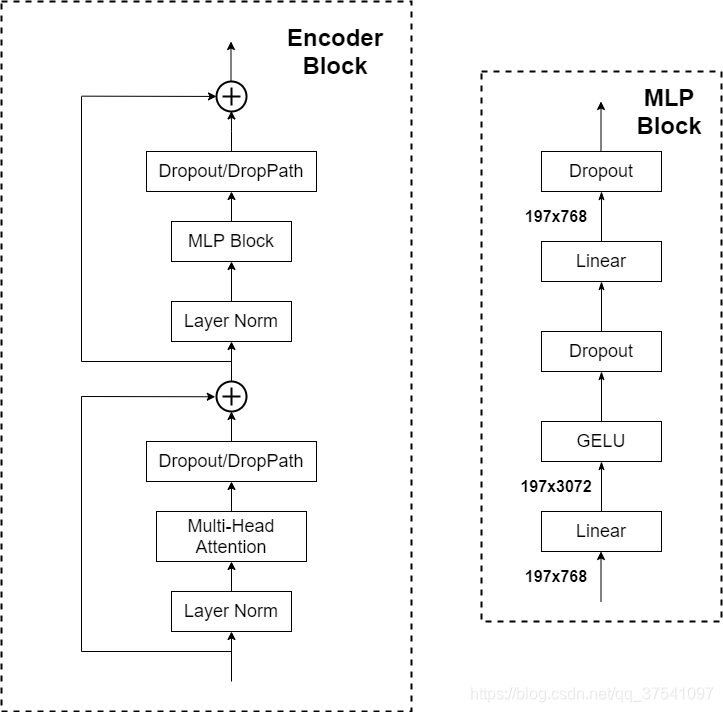
在 Transformer Encoder 前有一个 Dropout 层,其后有一个 Layer Norm 层。
MLP head
在训练 ImageNet21K 时,由 Linear+tanh+Linear 组成,而在训练 ImageNet1K 或是自己的数据时,由 Linear 组成。
整体结构
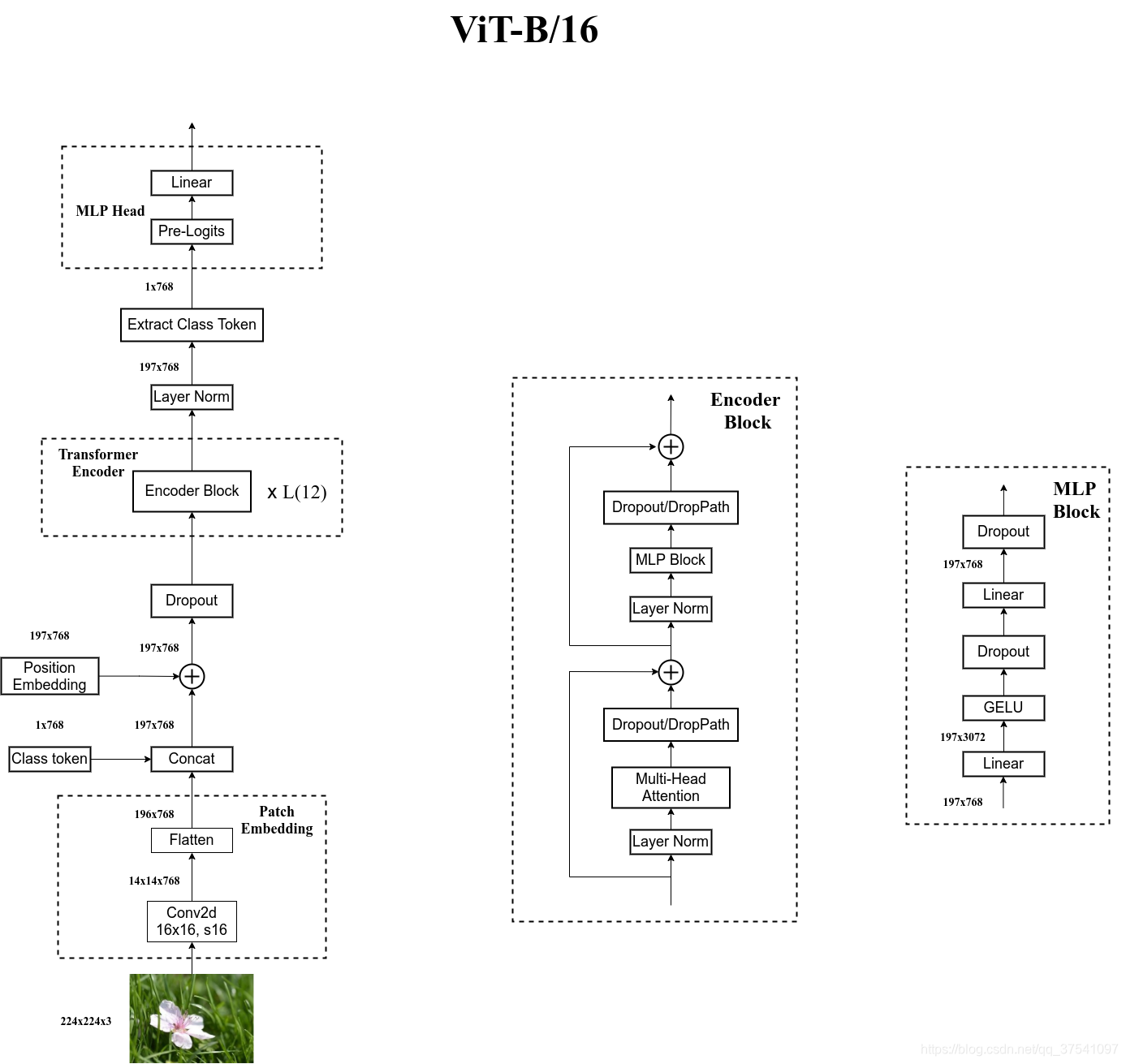
模型参数
| Model | Patch Size | Layers | Hidden Size D | MLP size | Heads | Params |
|---|---|---|---|---|---|---|
| ViT-Base | 16 x 16 | 12 | 768 | 3072 | 12 | 86 M |
| ViT-Large | 16 x 16 | 24 | 1024 | 4096 | 16 | 307 M |
| ViT-Huge | 14 x 14 | 32 | 1280 | 5120 | 16 | 632 M |
混合模型架构
Hybrid混合模型:将传统CNN特征提取和Transformer进行结合