Efficient Real-world Image Super-Resolution Via Adaptive Directional Gradient Convolution
论文地址:arxiv
摘要
背景
现实世界的图像超分辨率需要生成高分辨率且细节丰富的图像,但是现有的方法在处理复杂梯度区域时表现不佳。
创新点
提出了自适应方向梯度卷积(DGConv)。这种方法通过在卷积核中引入差分操作和可学习的方向梯度卷积,并结合线性加权机制,来增强对图像中梯度排列的感知能力。
正文
现实世界图像超分辨率
目标:从现实场景中捕获的低分辨率图像中重建高质量和高分辨率的图像。
对于 RealSR 任务,其挑战在于:准确感知低分辨率(LR)图像各区域纹理的空间排列特征,同时去除由退化线索引入的伪影,实现高质量的细节恢复。
现有的方法在细节恢复上取得了进展,但是在处理具有复杂梯度排列的区域时仍存在不足。
贡献点
- 提出了
DGConv,促进了细节相关,对比相关与降解相关属性的提取和平衡,提出了将 VConv 到 DGConv 的等效替换方法,可以在不增加计算成本的情况下进一卡提高现有的 SR 网络的性能。 - 为了平衡纹理与对比度的增强,提出了在特征空间的自适应信息交互模块。
- 基于
DGConv与AllBlock,提出了新的网络架构:方向梯度感知网络(DGPNet)
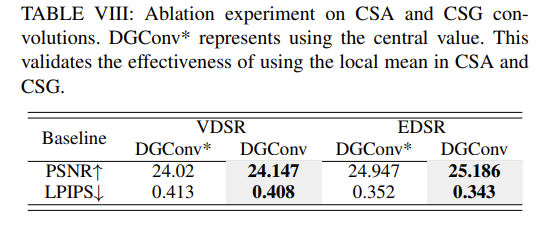
DGConv
DGConv 的结构如下:
产生的原因:VConv 在处理具有不规则方向梯度排列的区域时表现不佳,因为这些方法主要依赖于强度的线性加权特征提取方法。卷积难以有效利用相邻像素之间的差异来提取与细节相关的属性。图像退化会进一步扰乱固有纹理的空间排列特性和统计特性,使得增强图像细节和对比度更加困难。
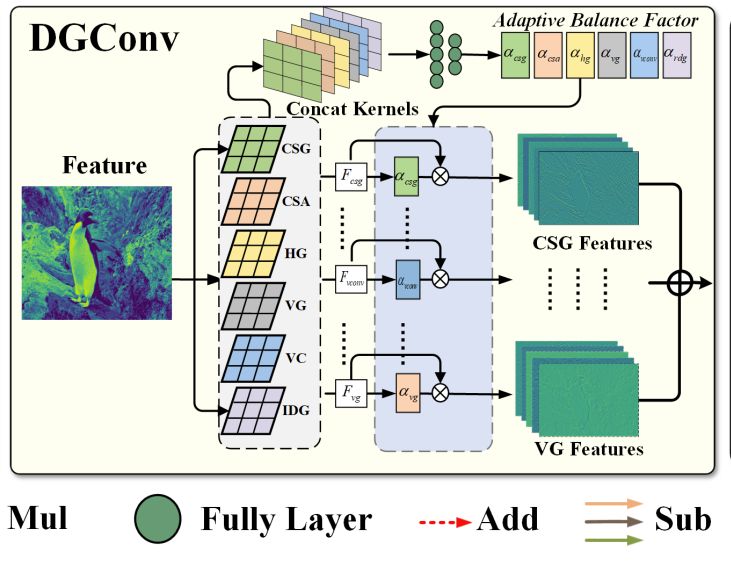
在卷积核中引入了基于核的差分操作,提出了若干可学习的方向梯度单元来增强方向感知能力,其中,有:
- 非规则方向梯度卷积(IDG)
- 规则方向梯度卷积
- 中心-周围梯度卷积(CSG)
- 垂直梯度卷积(VG)
- 水平梯度卷积(HG)
此外,还提出了在卷积核内引入聚合操作,提出了可学习的中心-周围聚合卷积(CSA)以增强对比度感知。这些单元以及 VConv 以核感知平衡机制并行集成,形成自适应方向梯度卷积(DGConv)。
对于每个 IDG,随机选择了一个位置作为中心像素,然后计算其余 N-1 点与中心点之间的梯度,其公式为:
$$
F_{idg}(X) = \sum_{i=1}^{9}\omega_{i}(x_{i}-x_{j}) \ \ \ \ \ x_{j} \in{x_{1},x_{2}, …,x_{n}}
$$
$x_{i}$ 为位置 $L_{i}$ 的特征强度,$x_{j}$ 是从卷积核覆盖的局部区域中随机采样的所有点。如果有 N 个核,卷积核大小为 K 时,理论上可以提取出 $NK*(K-1)$ 个方向的梯度,可以大大提高网络对非规则细节的感知能力。
由于人眼对重复排列的规则梳理更加第三,所以提取了利用局部统计均值与周围点之间的差异操作来获得水平,垂直与 45 度梯度,来促进规则梳理感知,将这种方法称为中心-周围梯度(CSG)卷积。其公式如下:
$$
F_{csg}(X)=\sum_{i=1}^{9}\omega_{i}*(x_{i}-\frac{1}{9}\sum_{i=1}^{9}x_{i})
$$
由于 CSG 只可以提取相邻两个像素的梯度。为了进一步提高梯度的丰富性,进一步在非相邻点之间进行差分操作,提出了可学习的水平梯度同(HG)卷积与垂直梯度(VG)卷积,其公式如下:
$$
F_{hg}(X) = \omega_1 \cdot (x_1 - x_3) + \omega_2 \cdot 0 + \omega_3 \cdot (x_3 - x_1) + \omega_4 \cdot (x_4 - x_6) + \omega_5 \cdot 0 + \omega_6 \cdot (x_6 - x_4) + \omega_7 \cdot (x_7 - x_9) + \omega_8 \cdot 0 + \omega_9 \cdot (x_9 - x_7)
$$
$$
F_{vg}(X) = \omega_1 \cdot (x_1 - x_7) + \omega_2 \cdot (x_2 - x_8) + \omega_3 \cdot (x_3 - x_9) + \omega_4 \cdot 0 + \omega_5 \cdot 0 + \omega_6 \cdot 0 + \omega_7 \cdot (x_7 - x_1) + \omega_8 \cdot (x_8 - x_2) + \omega_9 \cdot (x_9 - x_3)
$$
最后,由于存在低光,失焦模糊的情况,会降低图像对比度,所以在卷积过程中引入聚合操作,来促进对比度相关特性的建模。通过引入加法操作以抑制微小结构的影响,促进主要利用像素强度的对比度相关特性建模,并提出中心-周围聚合(CSA)卷积以加强恢复图像统计特性所需的统计信息的比例。公式如下:
$$
F_{csa}(X) = \sum_{i=1}^{9}\omega_{i}*(x_{i}+\frac{1}{9}\sum_{i=1}^{9}x_{i})
$$
通过以下方式将以上输出相连,可以得到融合结果。
$$
\omega_{\text{all}} = \text{cat}(\omega_{\text{idg}}, \omega_{\text{csg}}, \omega_{\text{csa}}, \omega_{\text{hg}}, \omega_{\text{vg}}, \omega_{\text{vconv}})
$$
再使用全连接层进行线性变换,即可得到 DGConv
$$
F_{DGConv} = \alpha_{\text{idg}} \cdot F_{\text{idg}} + \alpha_{\text{csg}} \cdot F_{\text{csg}} + \alpha_{\text{csa}} \cdot F_{\text{csa}} + \alpha_{\text{hg}} \cdot F_{\text{hg}} + \alpha_{\text{vg}} \cdot F_{\text{vg}} + \alpha_{\text{vconv}} \cdot F_{\text{vconv}}
$$
特征可视化:展示 IDG,VG,HG,CSG,CSA 的作用:

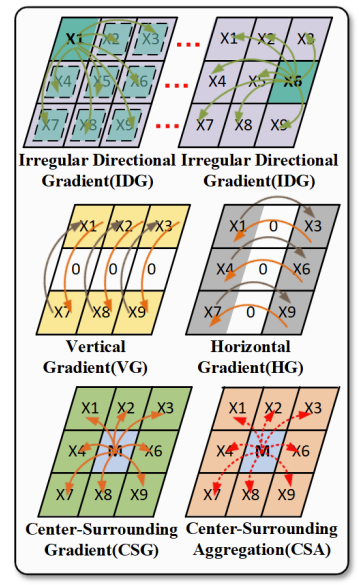
AllBlock
其结构如下:
由于 IDG,HG,VG,CSG 可以利用方向排列感知随机和多样化的方向梯度信息,而 VConv 与 CSA 可以利用统计和特征响应信息提取统计属性,因此将面向梯度的信息与面向对比度的信息分为两个分支,然后对它们进行排列,整合,并与不同分支的信息进行自适应交互。
使用以下公式,得到对应的拼接结果:
$$
X_g = \text{cat}(F_{\text{idg}}(X), F_{\text{csg}}(X), F_{\text{hg}}(X), F_{\text{vg}}(X))
$$
$$
X_c = \text{cat}(F_{\text{vconv}}(X), F_{\text{csa}}(X))
$$
$X_{g}$ 代表梯度导向的信息,而 $X_{c}$ 代表通道导向的信息。
使用 DGConv 获得两组 $X_{g1}$ 与 $X_{c1}$; $X_{g2}$ 与 $X_{c2}$,后,交叉串联来实现不同分支之间的信息集成。再使用 SE 模块自适应选择和加权每个分支的信息。并使用输入 X 作为残差学习以获得输出 O。
O 的计算公式如下:
$$
O = X + SE(\text{cat}(X_{g1}, X_{c2})) + SE(\text{cat}(X_{c1}, X_{g2}))
$$
DGPNet
DGPNet 直接堆叠 N 个 AIIBlock 作为骨干网络,使用像素重排来提高特征分辨率,并使用 DGConv 作为图像到特征和特征到图像的层。
其结构如下:

等效参数融合
作者提出的新的参数融合方法可以用于 DGConv,可以在推理过程中,将其复杂度简化到单个 VConv 的水平,同时保持其丰富的表示能力。
其核心思想是:先将提出的一个内核等同于 VConv 风格,然后将它们合并为一个 VConv 内核。如下图所示。
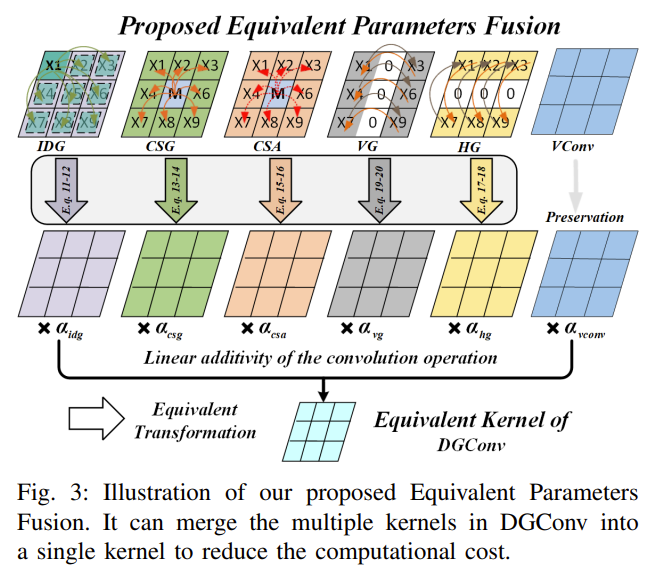
如 $F_{idg}(X) = \sum_{i=1}^{9}\omega_{idg}(x_{i}-x_{1})$ 可以转为 $\sum_{i=1}^{9}\omega^{}{idg}*x{i}$。其中,
$$
\omega^*_{idg} = \left{
\begin{array}{cccc}
\omega_{idg_1} - \omega_{idg_1}, & \omega_{idg_1} - \omega_{idg_2}, & \omega_{idg_1} - \omega_{idg_3}, & \omega_{idg_1} - \omega_{idg_1}, \\
\omega_{idg_4} - \omega_{idg_1}, & \omega_{idg_5} - \omega_{idg_1}, & \omega_{idg_6} - \omega_{idg_1}, & \\
\omega_{idg_7} - \omega_{idg_1}, & \omega_{idg_8} - \omega_{idg_1}, & \omega_{idg_9} - \omega_{idg_1}. &
\end{array}
\right}
$$
同时,$F_{csg}(X)$ 也可以转为 $\sum_{i=1}^{9}\omega^{8}{csg}*x{i}$ 的形式,$F_{csa}(X)$ 也可以转为 $\sum_{i=1}^{9}\omega^{8}{csa}*x{i}$ 的形式,$F_{hg}(X)$,$F_{vg}(X)$ 同理。
此时,可以得到可学习的随机方向梯度、中心-周围梯度、中心-周围聚合、垂直梯度、水平梯度卷积的等效 VConv 风格卷积核。然后利用卷积的线性可加性,将其拼接在一起,得到:
$$
F_{dg}(X) = \sum_{i=1}^{9}\omega_{f}^{}x_{i}
$$
其中,$\omega_{f}^{}=\alpha_{VConv}\omega_{VConv}^{}+\alpha_{lap}\omega_{lap}^{}+\alpha_{csa}\omega_{csa}^{}+\alpha_{hg}\omega_{hg}^{}+\alpha_{vg}\omega_{vg}^{}+\alpha_{idg}\omega_{idg}^{*}$
通过该方式,将 DGConv 的卷积核等同为单一的卷积核,其计算复杂度与普通的 VConv 相同,因此减少了 DGPNet 的计算成本。
损失函数
模型训练的损失函数使用 $L_{1}$,$L_{p}$,$L_{a}$,分别为 L 1 损失,感知损失,对抗损失。其公式为
$$
L_{total} = \lambda_{1}L_{1} + \lambda_{p}L_{p} + \lambda_{a}L_{a}
$$
对应的系数分别为 1.0, 1.0, 0.1
性能评估
DGPNet
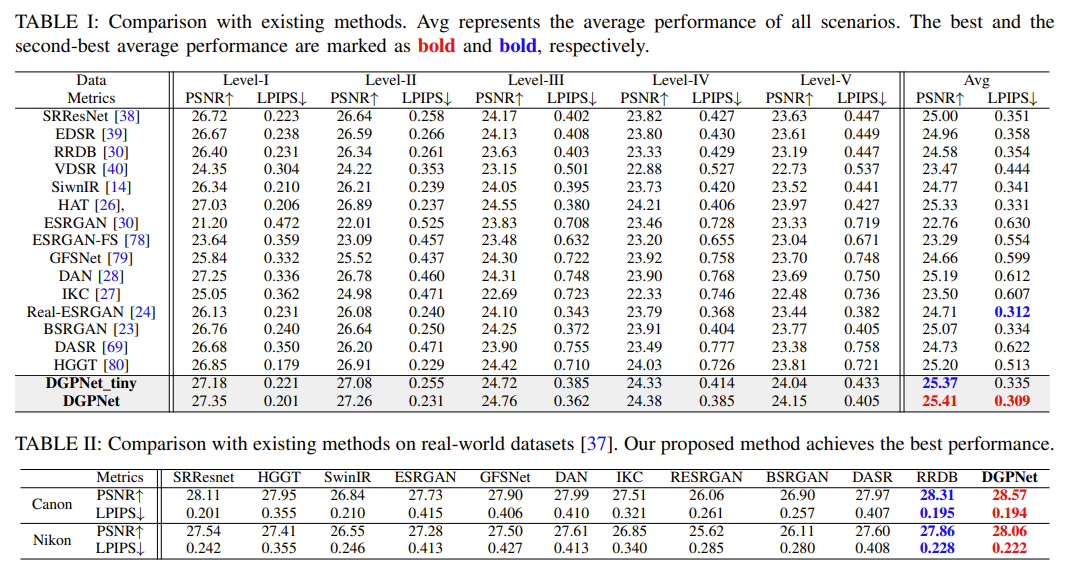
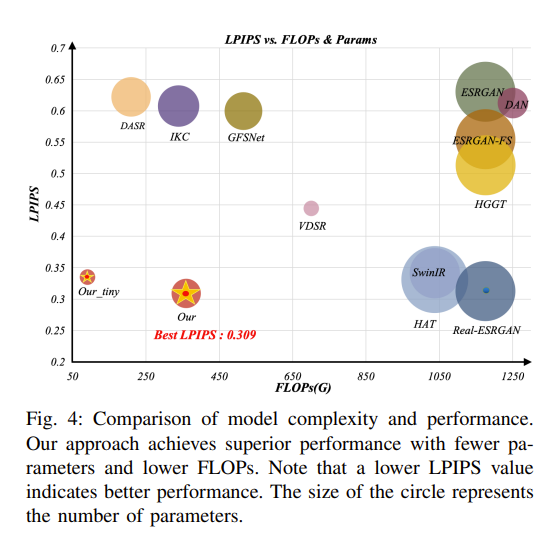
使用该模型与 15 种 Real-SR 的方法进行比较,可以得到以下的表,可以知道,在 PSNR 与 LPIPS 上能达到最佳性能,并显著超越现有的 SOTA 方法。
DGConv
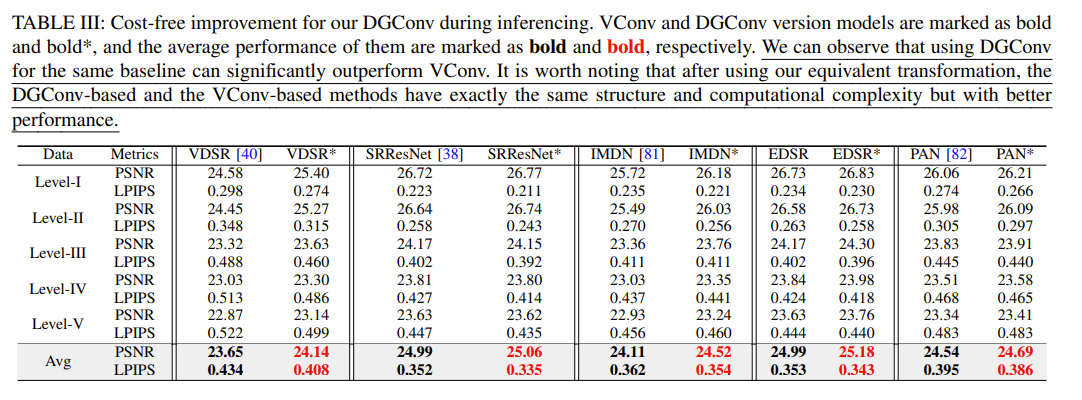
使用 DGConv 替换五种经典 SR 方法中的 VConv,可以发现其性能与准确率都有提升,因此可以证明:DGConv 可以应用于各种网络中,并可以插入现有网络中以提高性能。
消融实验
DGConv 的作用
对比 DGConv 与其他卷积单元,证明其在不增加额外计算成本的情况下提高网络表示能力的优越性。
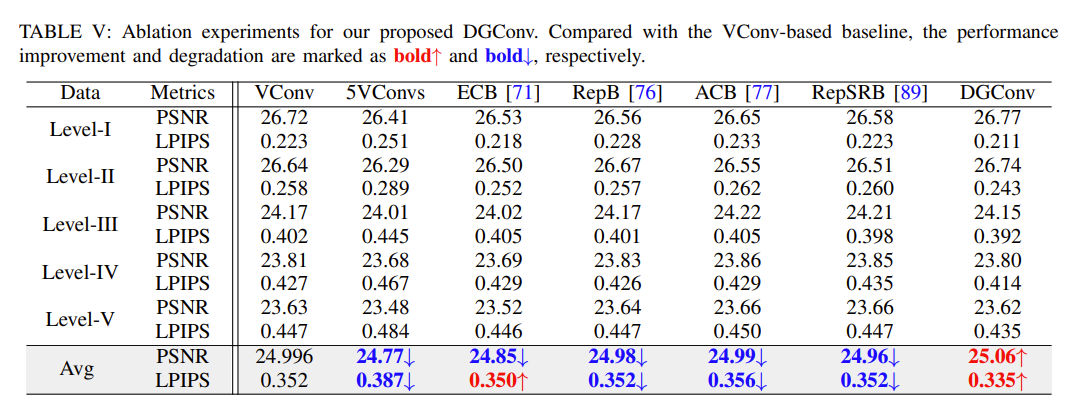
此外,还对 DGConv 中的每个卷积也进行了消融实验,表示每个卷积都在增强 DGConv 的表示能力方面都起了关键的作用:
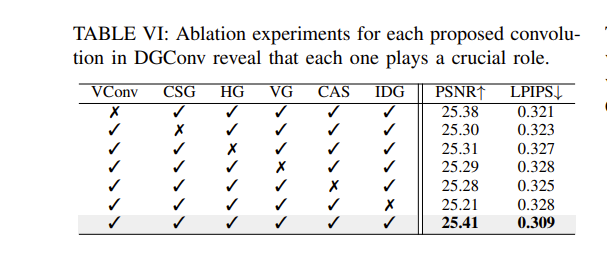
还对比了 DGConv 与 VConv 的计算成本与性能改进,证明了 DGConv 的优越性与即插即用特性。
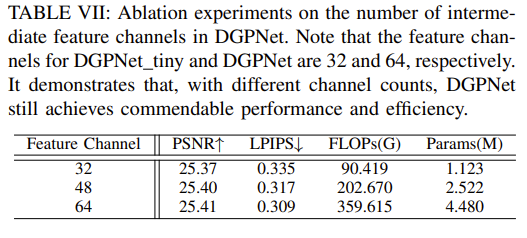
不同通道数对准确率的影响
可学习的卷积的优越性
将可学习卷积替换成了固定的手工设计的卷积后,DGPNet 和 SRResNet 的性能在 PSNR 上分别下降了 0.53 dB 和 0.87 dB。
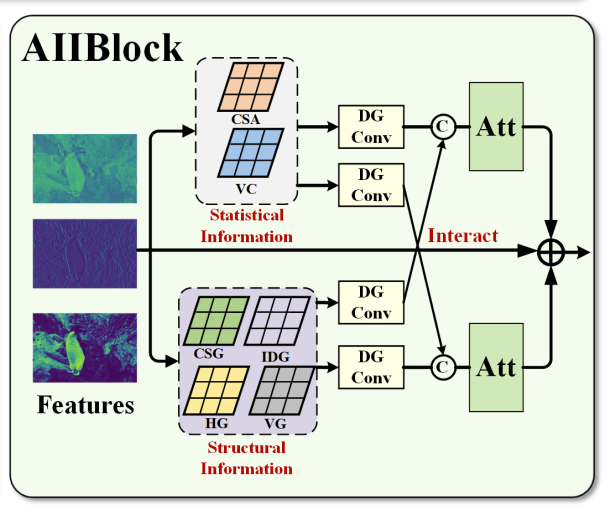
CSG 和 CSA 中使用局部统计均值的好处
由于 CSG 与 CSA 会使用局部均值来当做梯度参考,因此,要验证该做法是否正确,将局部均值更换成中心值后,可以发现以下变化,证明了使用局部均值的合理性。