LeMeViT- Efficient Vision Transformer with Learnable Meta Tokens for Remote Sensing Image Interpretation
论文地址:arxiv
摘要
当前的情况
遥感图像中存在空间冗余,因此,为了减少计算成本,通常会在自注意力(SA)机制中引入包含丰富信息的稀疏标记。这些标记的使用可以减少计算过程中需要处理的标记数量,从而避免视觉 Transformer 中的高计算成本问题。
存在的问题
然而,现在的方法通常通过手工设计或者是不好的并行设计来获得稀疏标记,但是这种方法会导致在效率和性能之间难以取得良好的平衡。
改进
LeMeViT 的目标:旨在有效解决传统注意力层的计算瓶颈问题。
本文提出,可以使用可学习的元标记来形成稀疏标记。这些元标记可以有效的学习关键信息,同时,又可以提高推理速度:
- 首先通过交叉注意从图像标记中初始化元标记。
- 使用双重交叉注意力机制(Dual Cross-Attention, DCA)。
结果
分类和密集预测任务的实验结果表明,与基线模型相比,LeMeViT 的速度显著提高了 1.7 倍,参数更少,性能更具竞争力,在效率和性能之间实现了更好的权衡。
正文
贡献
- 提出 LeMeVit 架构,效率更好
- 使用稀疏元标记来表示密集的图像标记
- 与具有代表性的基线模型相比,LeMeViT 在分类和密集预测任务中都取得了具有竞争力的性能。
LeMeVit创新点
- 提出使用极少量的可学习的元标记来表示图像标记,该方法不依赖于强先验知识。
- 提出了双交叉注意(DCA)来促进图像标记,该方法可以促进图像标记和元标记之间的信息交换,它们在双分支结构中交替充当查询标记和关键(值)标记,可以将传统自注意力的二次复杂度降至线性复杂度。
LeMeViT 架构
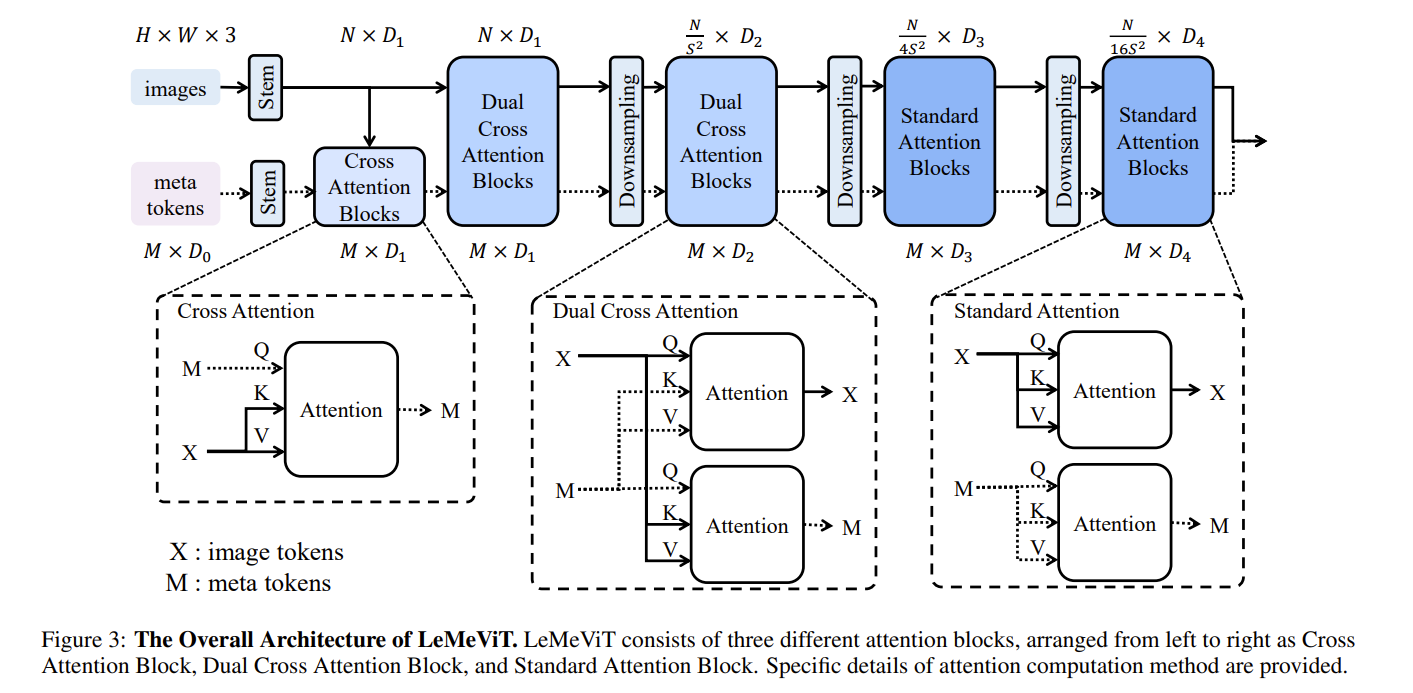
LeMeViT 采用分层式 ViT 结构,四个阶段使用下采样层连接。随着阶段的加深,图像特征的空间尺寸逐渐减小,而特征维度则不断扩大。模型的核心组件是元标记与 DCA 块。元标记首先通过交叉注意力从图像标记初始化。然后在第一阶段与第二阶段使用 DCA 来促进图像标记与元标记的信息交换。在第三阶段与第四阶段,使用基于自注意力的标准注意力块。
令图像标记为 $X \in \mathbb{R}^{N \times C}$ 元标记表示为 $M \in \mathbb{R}^{M \times C}$ C$ 表示标记维度,$N$ 和 $M$ 分别表示图像标记和元标记的数量,$D1, D2, D3$ 和 $D4$ 来表示不同阶段的标记维度。
可学习的元标记
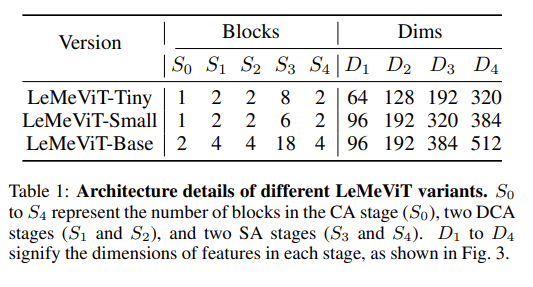
元标记是一组可学习的张量,能够通过与图像标记进行信息交换来更新。初始元标记在训练后是固定的,但它们会继续通过与图像标记的交互来更新。它们与图像标记一起作为模型输入。最初,元标记的形状是 M × D 0。随着图像标记的变化,元标记的维度会扩展,但长度始终保持为 M,经过实验,M 为 16 时最好。
Stem 块
图像传入的 stem 块
作用:将输入的图像划分成小块,并转入到标记(token)中.
具体的实现:使用两个 3×3 的卷积层,步幅为 2,填充为 1。卷积窗口以重叠方式滑动。
输出:经过两层卷积后,图像被划分成 4×4 大小的patch,每个 patch 对应一个标记。
元标记传入的 stem 块
Stem 块本来就只给 images 使用,但是为了使得元标记与图像标记的尺寸一致,所以也给元标记引入了一个 stem 块。该 stem 块的组成与图像的 stem 块的组成不一样。
该 stem 块由两个 MLP 层组成,经过处理后,元标记会被转换为与图像标记相同的特征维度。
下采样层
下采样层也使用了重叠的 patch 嵌入法,但只使用一个卷积来实现 2 倍的下采样率。
交叉注意力块(CA)
由于元标记在一开始是随机生成的,所以会与图像标记有较大的差距,此时不可以直接传入 DCA(可能会导致图像特征的崩溃与信息的丢失)。因此,可以使用图像标记,通过 CA 块,初始化元标记。
更新的公式可以描述为
$$
M = Attention(M_{Q}, X_{K}, X_{V})
$$
$M$ 为元标记,$M_{Q}$ 为元标记的查询投影,$X_{K}$ 与 $X_{V}$ 分别为图像标记的键与值的投影。
之所以 $Attention(M_{Q}, X_{K}, X_{V})$ 的结果可以表示元标记,是因为:
- 元标记的查询投影($M_{Q}$)与图像标记的键投影($X_{K}$)进行相似性计算,得到每个图像标记对元标记的重要性权重。这些权重反映了每个图像标记在当前元标记中的相关性。
- 使用这些权重对图像标记的值投影($X_{V}$)进行加权求和,得到的结果是一个综合了图像标记信息的新的特征表示。这些新的特征表示被赋予给元标记($M$),使得元标记能够更好地代表图像中的重要信息。
双重交叉注意力模块
DCA 模块是提高计算效率的核心组件。它用图像标记和元标记之间的两个交叉注意力代替了图像标记之间的成对自注意力,将计算复杂度从二次方$O(N^2)$降低到线性 $O(MN)$,其中,$M << N$,$M$ 表示元标记的数量,$N$ 表示图像标记的数量。
DCA 通过元标记隐式地保留了所有阶段的大部分图像信息。在 DCA 模块中,图像标记融合了元标记所持有的全局信息,同时又将每个图像块的局部信息聚合到元标记中。
DCA 模块的公式可以如下表示:
$$
X = Attention(X_{Q}, M_{K}, M_{V})
$$
$$
M = Attention(M_{Q}, X_{K}, X_{V})
$$
DCA 模块的计算量
DCA 模块与标准注意力模块的计算量的对比
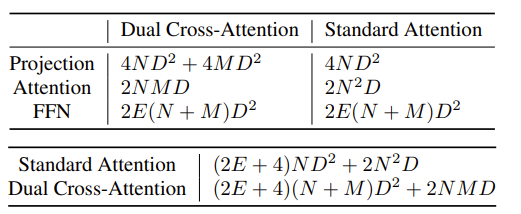
上表: DCA 和标准注意力中特定层的计算复杂度。下表两个注意力模块的总计算复杂度。
计算复杂度比使用标准注意力降低了约 10 倍。
标准注意力模块
通过使用标准注意力机制,可以保证模型的效率与性能:当阶段(stage)加深,图像的标记会减少,此时,$M << N$ 的假设会不成立,此外,当维度增加,投影层引起的计算量开销也会变得很大,所以如果还使用 DCA,其计算的效率不会比标准自注意机制高。
尾处理
图像标记和元标记分别通过全局平均池化处理,然后加在一起进行分类预测。此外,在每个阶段中,只有不同尺度的图像标记被用于执行密集预测任务。
LeMeViT 不同的规模
模型评估
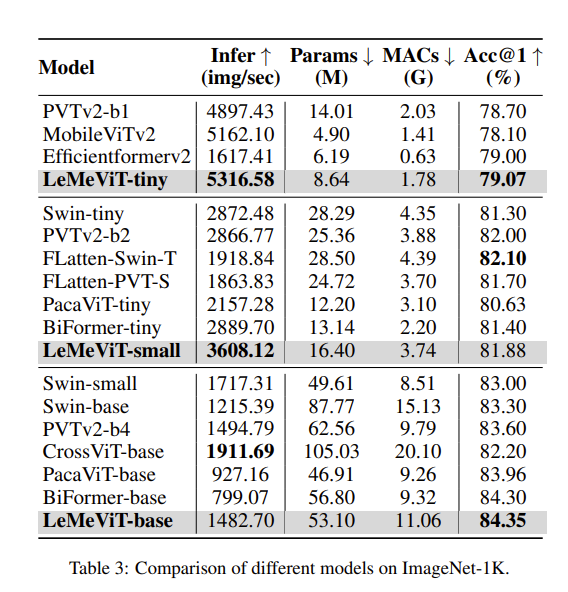
ImageNet 1 k
在 ImageNet-1 K 上,该模型与其他模型的对比
MillionAID
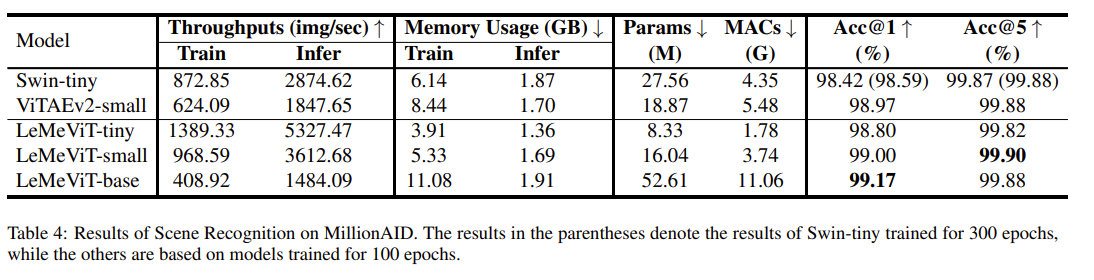
遥感下游任务
在目标检测,变化检测中,与先进的模型准确度基本一样,但是计算量减少了很多,在语义分割中,其先进的模型准确度基本一样。
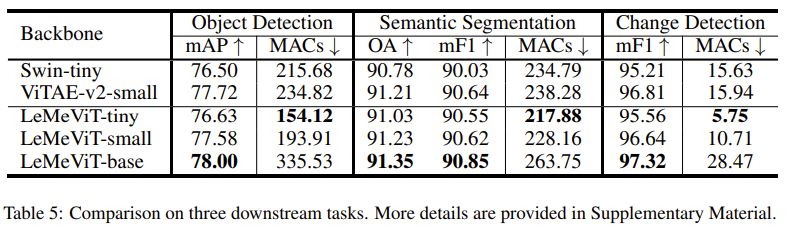
消融实验
主要调查:元标记长度的影响。
结果:元标记符的长度对性能的影响微乎其微。当长度为 64、32、16 和 8 时,准确率几乎相同 -> 图像中冗余的部分很多。
经过消融实验,使用 16 作为元标记的长度。
以下是不同长度的元标记对准确率的影响:
更多消融实验(附录)
- 交叉注意力块(Cross Attention block):通过移除该模块并测试模型的准确性,来评估其对分类任务的影响。
- 元标记干层(meta token stem):通过移除该层并调整元标记的初始维度来匹配干层的输出维度,评估其对模型性能的影响。
- 标记融合(token fusion):在原始模型中,图像标记和元标记通过全局池化后相加进行分类。在消融实验中,仅使用图像标记进行分类,不进行元标记池化,以评估这一设计的作用。
经过测试,这些设计都是有利于提高准确率的。
知识点
强先验知识
强先验知识(strong priors)在机器学习和统计学中指的是对模型或数据的强烈预设或假设。这些假设通常基于领域知识或经验,并在模型训练之前被明确地引入。强先验知识可以帮助模型更快地收敛并提高性能,但也可能限制模型的灵活性和泛化能力,因为它们可能会忽略数据中的一些潜在模式或信息。
卷积窗口以重叠方式滑动
在卷积操作中,卷积核(或滤波器)在输入图像上移动时,每次移动的步幅(stride)小于卷积核的尺寸,从而导致相邻的卷积窗口之间有部分重叠。这种方式可以捕捉更多的局部信息,因为每个像素点可能会被多个卷积窗口覆盖。