Mamba or RWKV- Exploring High-Quality and High-Efficiency Segment Anything Model
论文地址:arxiv
摘要
背景
基于 Transformer 的分割在处理高分辨率的图像时有着困难,而线性注意力机构,比如 Mamba 与 RWKV,因其可以高效处理长序列而引起关注。
创新
作者通过探索不同的架构来设计一个高效的分割任何东西的模型。
设计了一个包含卷积和 RWKV 操作的混合骨干网络(mixed backbone),在准确性与效率都达到了最佳。还设计了一个高效的解码器,利用多尺度的 token 来获得高质量的掩码。
作者将他们的方法称为 RWKV-SAM,这是一个简单,有效,快速的 SAM 类模型基线(baseline for SAM-like models)。还构建了一个包含各种高质量分割数据集的基准(benchmark),并使用该基准共同训练了一个高效且高质量的分割模型。
正文
背景
SAM 由于在众多分割任务中的能用性与有效性,所以有很多的关注,但是其计算成本很高,并且在情况下仍然不足。因此这限制了 SAM 在实时场景和需要高质量分割结果的领域中的应用。现有的工作通常只关注解决第一个问题或第二个问题。
而最近出现了线性注意力模型,该模型可以处理非常长的序列,同时保持其全局感知能力。由于没有使用该模型来在类似 SAM 的可揭示分割任务上探索这些架构,所以作者解决了该问题。
作者提出了 RWKV-SAM 来处理 SAM 的计算成本与分割质量问题。SAM 的高计算成本可以归因于两个原因:1. 巨量的参数 2. 随着输入特征大小的增加,Transformer 层中的注意力设计引起的二次时间复杂度。作者通过 RWKV 在保持全局感知的同时提高高分辨率下的效率。
高效分割骨干网络有三个阶段,解码器可以用来细化生成的掩码。
贡献
- 提出了 RWKV-SAM,包含了一个分割骨干网络,生成不同分辨率的特征图,并利用 RWKV 操作来降低时间复杂度。
- 在解码器中用多尺度特征图,并在高质量分割数据集上训练 RWKV-SAM
- 在几个基准上展示了 RWKV-SAM 的有效性。
- 对各种线性注意力模型,进行了详细的比较研究。
相关工作
高效分割
现有的高效分割方法主要集中在封闭集和特定领域。许多高效分割研究专注于驾驶场景。此外,多个研究致力于高效全景分割和快速视频实例分割。
高效骨干网络
这一方向主要集中在开发高效的卷积神经网络(CNN),Transformer 与混合架构。在机器学习中,最近的研究集中在线性注意力模型,如 RWKV 与 Mamba。但是这些工作忽略了在不同尺度上生成特征。
作者采用了 CNN 与 RWKV 的混合架构。
高质量分割
以前的研究通过设计特定模块、提出细粒度数据集和添加精细化器来实现高质量分割,但这些方法通常无法实时运行。我们的目标是设计一个新模型,实现实时高质量分割,并建立一个完整的训练管道(training pipeline)。
线性注意力模型
Transformer 有着计算成本的问题。而状态空间模型(SSM)可以被证明能建模长程依赖,并且,RWKV 是另一种具有更快推理速度的方法。
在高分辨率的图像僌的高效分割设计下,RWKV 比 Mamba 更快,所以作者使用 RWKV 作为骨干网络。
模型架构
作者认为设计的模型应该有以下的特性:
- 在高分辨下也可以保持高效的主干网络(backbone)
- 模型应该可以利用现有的 SAM 知识,来避免在整个上
SA-1B数据集上进行训练 - 模型应该可以利用来自主干的特征金字塔 (feature pyramid),并使用高质量的数据进行训练,以生成高质量的掩码(masks)
作者设计出的模型有以下的特点:
- 该网络有特征金字塔
- 在高分辨率下高效,同时在性能上优于其他的 transformer 或线性注意力模型
高效的分割骨干网络
借鉴了 NLP 社区中线性时间序列建模的理念,提出了一种基于 RWKV 的高效视觉骨干网络:有三个阶段的设计,包含了两件中类型的模块:移动卷积模型(MBConv)和视觉 RWKV 模块(VRWKV)。
骨干网络的总体架构
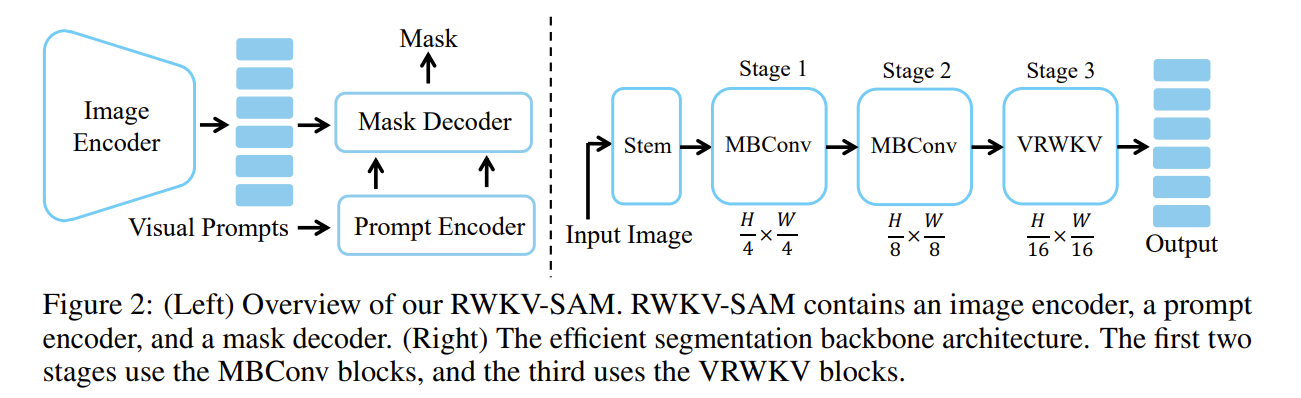
左边的是 RWKV-SAM 的概述;右边的是分割主干架构,前两个阶段使用 MBConv,第三个阶段使用 VRWKV 块。
在前两个阶段中,采用基于卷积的模块,即 MBConv,生成高分辨率的特征图。每个阶段之前都将特征图下采样 2 倍。这些高分辨率的特征图可以在解码器中用于掩码细化。在第三个阶段之前,特征图的下采样因子为 16,所以特征图中的每个像素可以看作一个 token。在第三个阶段,堆叠了一系列 VRWKV 模块,将这些 token 输入。
与普通的视觉 transformer 或视觉 RWKV 相比,作者的骨干网络具有不同尺度的特征图,而不是单一固定的分辨率。以下是不同变体的设计:
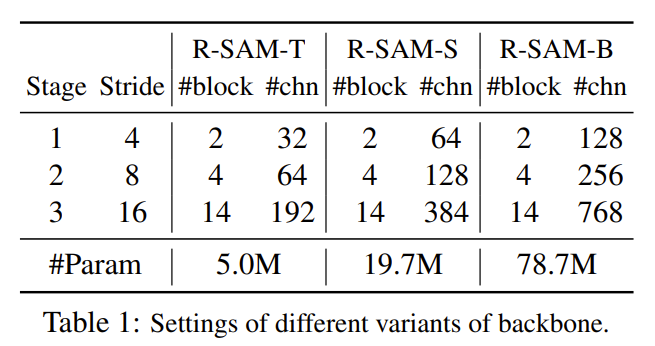
微层次设计
MBConv 块使用了倒置瓶颈设计。它包含了一个 1*1 卷积用于扩展通道大小,一个 3*3 深度卷积用于空间混合,以及另一个 1*1 卷积通道投影回原始大小。
作者使用 LayerNorm 来简化设计。在 MBConv 块中将扩展比设置为 4,对于 VRWKV 块,令 token 首先经过空间混合模块,然后再进入通道混合模块。空间混合模块起到了全局感知的作用。
如果输入的 token 可以表示为 $X$,$L$ 为 token 长度,$C$ 为通道大小,空间混合模块以 $Q-shift$ 模块开始:
$$
R_s=Q-Shift_R(X)W_R, K_s = Q-Shift_K(X)W_k, V_S=Q-Shift_V(X)W_V
$$
Q-Shift 是一个重要的模块,因为它允许每个 token 与四个方向的像素邻域进行插值,保持图像特征的局部性,并已被证明是有效的:
$$
Q\text{-}Shift(X) = X + (1 - \mu)X’
$$
其中 $X’$ 是通过沿通道维度结合每个 token 周围的四个像素得到的 token。$\mu$ 是一个可学习的超标量,每个表征都不同。
在混合像素邻域后,空间混合模块全局且双向地融合 token:
$$
O_s = (\sigma(R_s) \odot \text{Bi-WKV}(K_s, V_s)) W_O
$$
$\sigma$ 表示 sigmoid 函数,$\odot$ 是元素级乘法。Bi-WKV 是注意力机制的关键组件,使得每个 token 可以与序列中的所有其他 token 进行全局交互。对于序列中的索引为 t 的每个 token,输入为 $K_s$ 和 $V_s$ 可以有以下的计算:
$$
\text{Bi-WKV}(K, V)t = \frac{\sum{i=0, i \neq t}^{L-1} e^{-(|t-i|-1)/L \cdot w + k_i} v_i + e^{u + k_t} v_t}{\sum_{i=0, i \neq t}^{L-1} e^{-(|t-i|-1)/L \cdot w + k_i} + e^{u + k_t}}
$$
$w$ 与 $u$ 是序列中共享的参数,$k_i$ 与 $v_i$ 分别对应于索引 i 处的特征 $K_s$ 与 $V_s$。Bi-WKV (K, V) 可以转换为 RNN 形式,以线性计算复杂度并行执行。
在空间混合模块之后,toekn 被送往通道混合模块:
$$
R_c = Q\text{-}Shift_R(X)W_R
$$
$$
K_c = Q\text{-}Shift_K(X)W_K
$$
$$
O_c = (\sigma(R_c) \odot \text{SquaredReLU}(K_c)W_V)W_O
$$
通道混合模块独立地对每个 token 进行计算,类似于 MLP,但它添加了 Q-Shift 以进一步保持图像特征的局部性。特别地, $W_K$ 将嵌入投影扩展为原来的两倍, $W_V$ 将嵌入投影回原始大小。
数据,模型与训练流程介绍
原始的 SAM 使用了一个庞大的 ViT-H 骨干网络和一个轻量的解码器,能够处理大规模的图像数据。为了提高效率和质量,RWKV-SAM 在训练数据、模型结构和训练流程上进行了改进。
在训练数据方面,RWKV-SAM 引入了三个新的数据集:COCONut-B、EntitySeg 和 DIS 5 K。这些数据集包含了高质量的人工标注图像,弥补了原始自动标注数据集的不足。
在模型结构方面,RWKV-SAM 设计了一个三阶段的骨干网络,前两个阶段可以用于低级局部特征,第三阶段的输出可以用作全局特征。通过保留原始 SAM 的提示编码器和解码器,并引入额外的细化模块,RWKV-SAM 能够生成更准确的掩码。
原始的 SAM 生成掩码特征的过程如下:
$$
F_M = \Phi_{\text{dec}}(\Phi_{\text{pe}}(P), X)
$$
$\phi_{pe}$ 为编码器,$\phi_{dec}$ 为解码器,$F_M$ 为掩码,$P$ 为视觉提示。
而额外的细化模块的过程如下:
$$
F’M = \Phi’{\text{dec}}(F_M, X, X_{mr}, X_{hr})
$$
$X_{hr}$ 为第一阶段的输出,$X_{mr}$ 为第二阶段的输出,$F’_M$ 为细化后的掩码特征。
作者设计了几种细化模块的设计,并使用了两个卷积层来融合特征,来简化与提高效率。细化后的掩码特征可用于生成掩码输出:$M = Q \cdot F’_M$,$Q$ 为生成的实例,$\cdot$ 表示每个掩码的点积。
训练流程
训练的过程分别两个步骤:
- 骨干网络对齐
使用原始的 SAM(具体为 VIT-H 模型)来训练一个高效的分割骨干网络。
使用每像素均方误差(MSE)损失来确保新训练的骨干网络与 VIT-H 的输出一致,其损失函数为:
$$
LS1 = \text{MSE}(X_{\text{SAM}}, X)
$$
$X$ 为 RWKV-SAM 的网络输出,$X_{SAM}$ 为 SAM 中 VIT_H 骨干网络的输出。
- 联合训练
利用组合数据集对整个模型进行联合训练。对于每个图像,先根据掩码标注生成每个实例的边界框,并随机选择最多 20 个实例进行训练。通过 RWKV-SAM 基于视觉提示生成掩码后,应用掩码交叉熵(CE)损失与 Dice 损失,计算生成掩码与真实掩码之间的损失。第二步的损失公式为:
$$
L_{S2} = \lambda_{\text{ce}} L_{\text{ce}} + \lambda_{\text{dice}} L_{\text{dice}}
$$
同时,两个系数均为 5.
模型评估
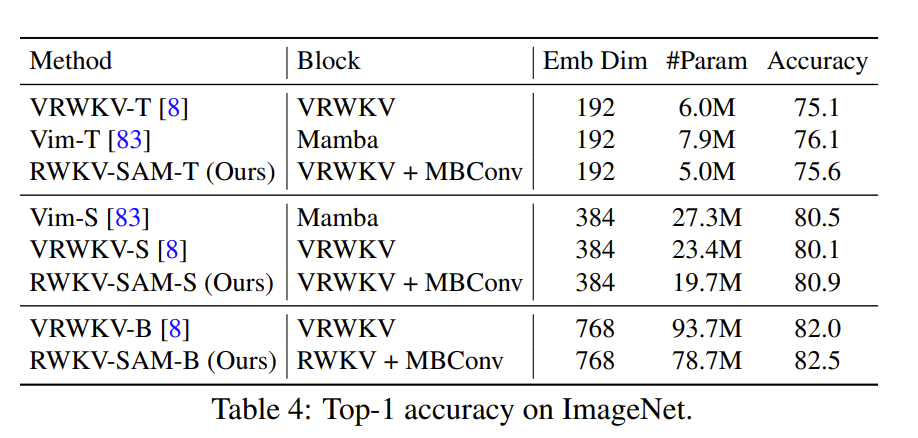
在参数数量较少的情况下,该方法比基于 Mamba 或 RWKV 的前期方法表现更好或相当。
作者认为,这种改进可能得益于宏观设计,它在前两个块中使用卷积层来获取不同尺度的特征,而不是直接通过将图像转换为图像块来下采样。
语义分割
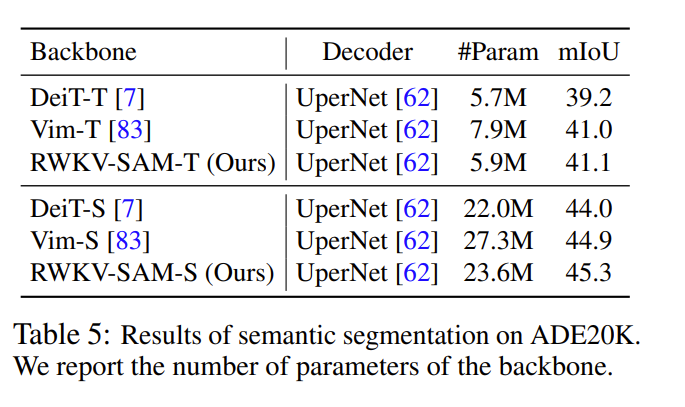
分割任何模型
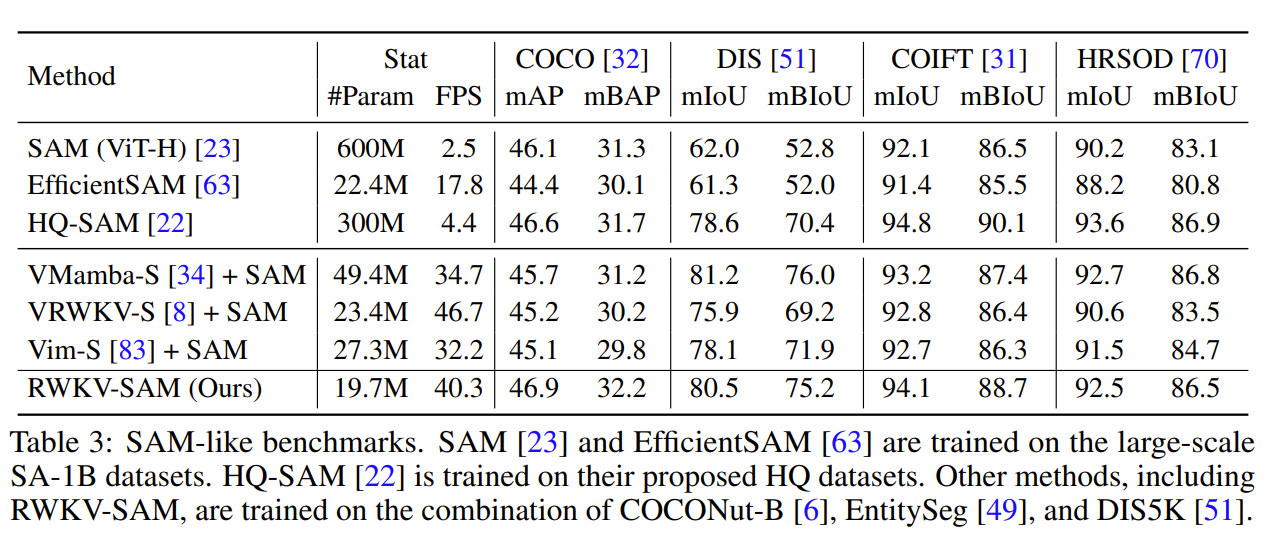
RWKV-SAM 在多个基准测试中表现出色,特别是在高质量数据集和零样本学习任务中,优于其他现有方法。
消融实验
效率分析
该部分分析了 RWKV-SAM-Small 和 ViT-Small 在不同输入图像尺寸下的延迟表现。测试结果显示,RWKV-SAM-Small 在高分辨率图像输入时具有更好的延迟表现,特别是在 1024 x 1024 的输入尺寸下,其 FPS 显著高于 ViT-Small,这表明 RWKV-SAM-Small 具有更高的计算效率。
解码器中融合模块的效果
作者使用了不同的设计来融合来自不同试炼的特征。使用这些设计的结果如下:
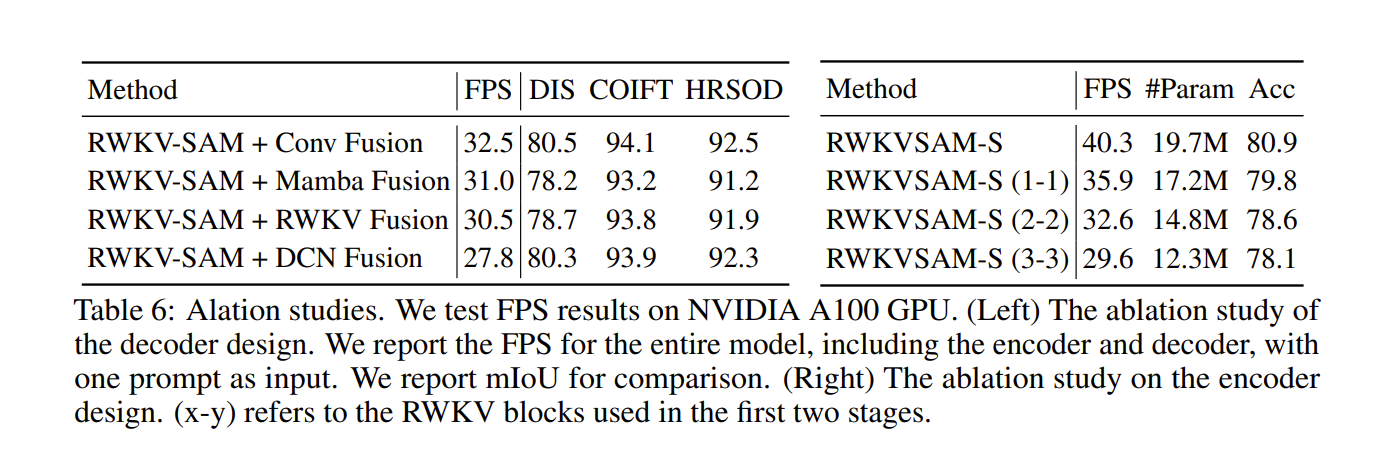
第一个设计的在效率上最佳,同时在性能上也与其他设计相当。第一个设计的结果如下:每个尺度使用两个卷积层来下采样低级特征并对齐通道,然后在融合三个特征后沿通道维度再使用两个卷积层。
编码器设计的消融实验
作者尝试在第一个阶段中添加一些 RWKV 块,来评估宏观层面的设计。其结果为上图的右表。可知,在前两个阶段添加更多 RWKV 块会降低推理速度和模型性能,因此将 RWKV 块放在第三阶段是更优的设计。
可视化

通过对比可视化结果,展示了 RWKV-SAM 在复杂场景中的优越分割质量,特别是在细节处理上优于其他方法。