ViG- Linear-complexity Visual Sequence Learning with Gated Linear Attention
论文地址:arxiv
摘要
背景
线性复杂度序列建模网络在各种计算机视觉任务中的建模能力已经达到了与 vision transformer 相似的水平,同时使用了更少的 FLOPs 与内存,然而,在实际中的运行速度方面的优势并不显著。
改进
进入了视觉的门控线性注意力(GLA),利用其硬件感知与效率。
正文
线性时间序列建模方法
该方法类似于 RNN,通过将所有历史输入压缩到一个固定大小的状态,然后基于这个压缩状态注意当前输入,不像 Transformer 那样关注所有的历史状态。
贡献
- 提出了 ViG,结合了
Gated Linear Attention(GLA)的线性复杂度高效视觉序列学习所需的硬件感知性。解决了基于 Transformer 和基于 CNN 的方法的局限性,结合了两者的优点,提供了一种高效且可扩展的解决方案 - 提出了三个关键的设计:一种双向门控线性注意机制,可以捕捉视觉序列的一维全局上下文;一种方向性门控机制以自适应地选择来自不同方向的全局上下文;一种二维门控局部注入,以将二维局部信息整合到一维全局上下文中。进一步提供了硬件感知的实现,将前向与后向扫描合并到一个内核中,增强了并行性并减少了内存成本与延迟。
从标准 softmax 注意力到先进的门控线性注意力(GLA)的演变
Softmax 注意力因为它有动态建模长序列关系的强大能力,并且在训练或具有很好的并行性,所以一直被 Transformer 使用。在自回归 Transformer 中使用的 softmax 注意力可以定义为:
$$
Q, K, V = XW_Q, XW_K, XW_V
$$
$$
O = \text{softmax} ((QK^T) \odot M ) V
$$
其中,$X$ 为输入的序列,$W_{Q}$,$W_{K}$,$W_{V}$ 为可训练的投影矩阵,$M \in {-\inf,1}^{T*T}$ 是防止与未来标记交互的因果掩码,$O$ 为输出。以上的并行形式也可以写成以下递归形式来计算单个输出 $o_{t}$:
$$
q_t, k_t, v_t = x_t W_Q, x_t W_K, x_t W_V
$$
$$
o_t = \frac{\sum_{i=1}^{t} \exp(q_t k_i^T) v_i}{\sum_{i=1}^{t} \exp(q_t k_i^T)}
$$
线性注意力是用特征映射点积 $\phi(q_{t})\phi(k_{i})^{T}$ 来代替标准 softmax 中的 $\exp(q_{t}k_{i}^{T})$。在最近的实验中,又证明了线性特征映射在设置 $\phi$ 为恒等映射并移除归一化器的情况下效果很好,所以简化 $o_{t}$ 的计算为:
$$
o_{t}=q_{t}\sum_{i=1}^{t}k_{i}^{T}v_{i}
$$
令隐藏状态 $S_{t}=\sum_{i=1}^{t}k_{i}^{T}v_{i}$,它是固定大小并压缩了历史信息,可以将上述计算制定为一个 RNN:
$$
S_{t}=S_{t-1}+k_{t}^{T}v_{t}
$$
$$
o_{t}=q_{t}S_{t}
$$
门控线性注意力 (GLA)提出了在线性注意力中添加数据依赖的门控机制来增强表达能力。其公式可以描述为:
$$
\alpha_t = sigmoid((x_t W^1 \alpha W^2 \alpha + b\alpha))^ \frac{1}{\tau}
$$
$$
G_t = \alpha^T_t1 \in (0, 1)^{d_k \times d_v}
$$
$$
S_t = G_t \odot S{t-1} + k^T_t v_t \in \mathbb{R}^{d_k \times d_v}
$$
$$
o_t = q_t S_t
$$
其中,$\alpha_t$ 是能对这对 $x_t$ 应用一个低秩线性层并经过 sigmoid 激活函数得到的。而 $W_1^\alpha$,$W_2^\alpha$ 与 $b_\alpha$ 是可训练的矩阵,$\tau=16$ 是一个温度项,用于鼓励模型具有较慢的遗忘率,$G_{t}$ 为矩阵正式工的遗忘门,通过与矩阵 1 外积扩展得到。
网络总体结构与处理流程
- 图像转换:原始的图像是一个
H*W*3的图像,将该图像分割成多个小的图像 patch,每个 patch 的大小为p*p。通过分割,图像被转换成 T 个 patch token,其中 $T=H*W / p^2$。每个 patch token 有 d 维度的特征表示。 - 位置嵌入:在将这些 patch 输入到 ViG 块之前,要先添加可学习的位置嵌入,这些位置嵌入帮助模型理解 patch 在原始图像中的位置,从而保留空间信息。
- 将 patch token 输入到一系列 ViG 块中
- 最后的 ViG 块的输出标记被输入到一个全局平均池化层,这个池化层将整个特征图的平均值计算出来,生成一个固定大小的特征向量。
- 之后会被输入到一个线性分类器中,用于最终的分类任务
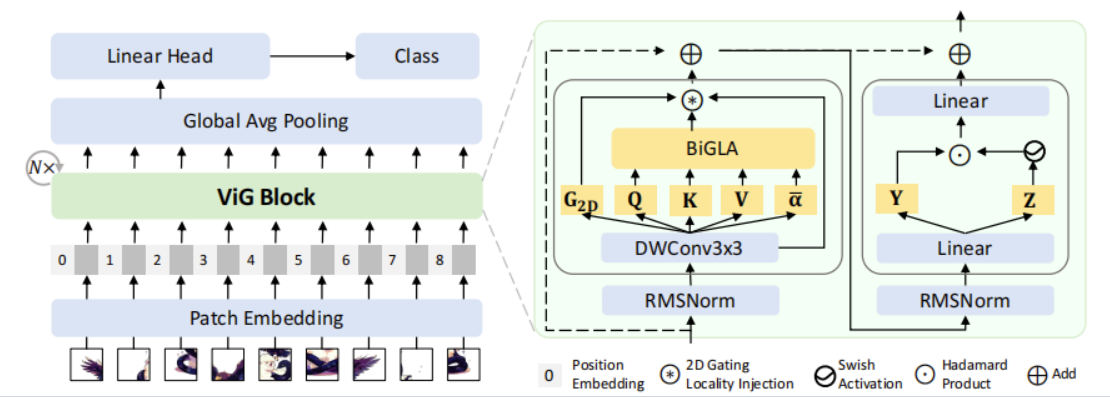
ViG 模块
ViG 模块由以下部分组成:
- 一个长期的 BiGLA 层,可以以线性复杂度利用图像的一维全局上下文。
- 一个短期的深度卷积层,可以捕捉图像的二维局部细节。
- 一个可以自适应地结合全局和局部信息的门控机制。
- 一个用于通道混合的 SwiGLU 前馈神经网络(FNN)层。
全局双向门控线性注意力 (Global Bidirectional Gated Linear Attention)
双向建模:简洁并且内存友好。该设计的关键在于方向性的门控机制,特别是遗忘门 $G_{t}$,可精确控制信息流动,这对于位于物体边界的标记很重要,因为来自不同方向的信息在重要性上有很大差异。
为了可以有效利用这种方向敏感性,引入了 BiGLA 层,该层如下图所示:
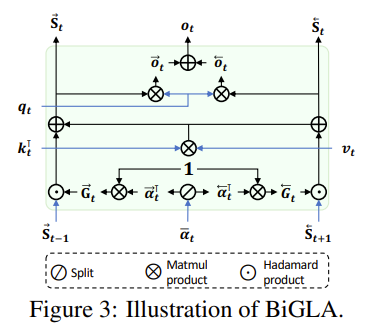
该层通过共享除遗忘门外的所有参数来实现参数效率,遗忘门则针对每个方向进行调整,公式如下所示:
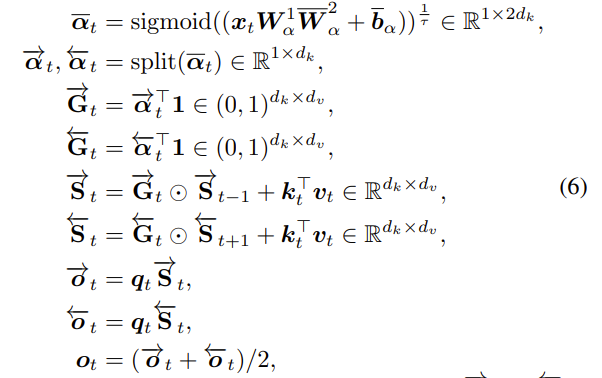
$\overline{\Box}$ 表示双向修改,$\overrightarrow{\Box }$ 与 $\overleftarrow{\Box }$ 分别表示前向与后向。提出的 BiGLA 层将前向与后向方向的历史信息压缩到固定大小的隐藏状态 $\overrightarrow{S_{t}}$ 与 $\overleftarrow{S_{t}}$,并且与隐藏状态一起关注 $q_{t}$ ,以线性复杂度获取长期全局上下文。这个设计对比于整体网络来说,增加的参数量很小。而使用的 FLOPs 则为:
- BiGLA= $5Td^2+32Td$
- softmax= $4Td^2+2T^2d$
2 D 门控局部注入(2 D Gating Locality Injection)
为了改善二维图像的局部细节,引入了短期局部卷积层来注入二维局部性。在具体实现中,使用了 3*3 的 DW 卷积。
受到 GLA 中数据依赖门控机制的启发,提出了数据依赖的门控聚合用于二维局部注入,来交织全局与局部信息可由以下公式表示:
$$
O_{local}=DWConv_{3*3}(X)
$$
$$
O_{global}=BiGLA(O_{local})
$$
$$
G_{2D}=sigmoid(O_{local}W_{gate2D}+b_{gate2D})
$$
$$
O=G_{2D} \odot O_{local}+(1-G_{2D}) \odot O_{global}
$$
架构细节
提出了两种 ViG 模型变体,一种是 ViT 风格的非层次模型,每个模块中有固定数量的 token,一种是 CNN 风格的层次模型,token 逐渐下采样。
高效实现
如果要实现高效运算,则要
- 了解内存层次结构
- 利用专门的计算单元
- 具有高度的并行性
可以通过在 SRAM 上执行矩阵简洁而不是在较慢的 HBM 上执行,可以关注 HBM 的 IO 成本,并利用张量核心提升了计算效率。
此外,还可以优化双向设计:之前的方法是将前向与后向方向分别处理,而新的方法则是将其融合到一个内核中,提高了并行性与计算效率。
模型评估
图像分类
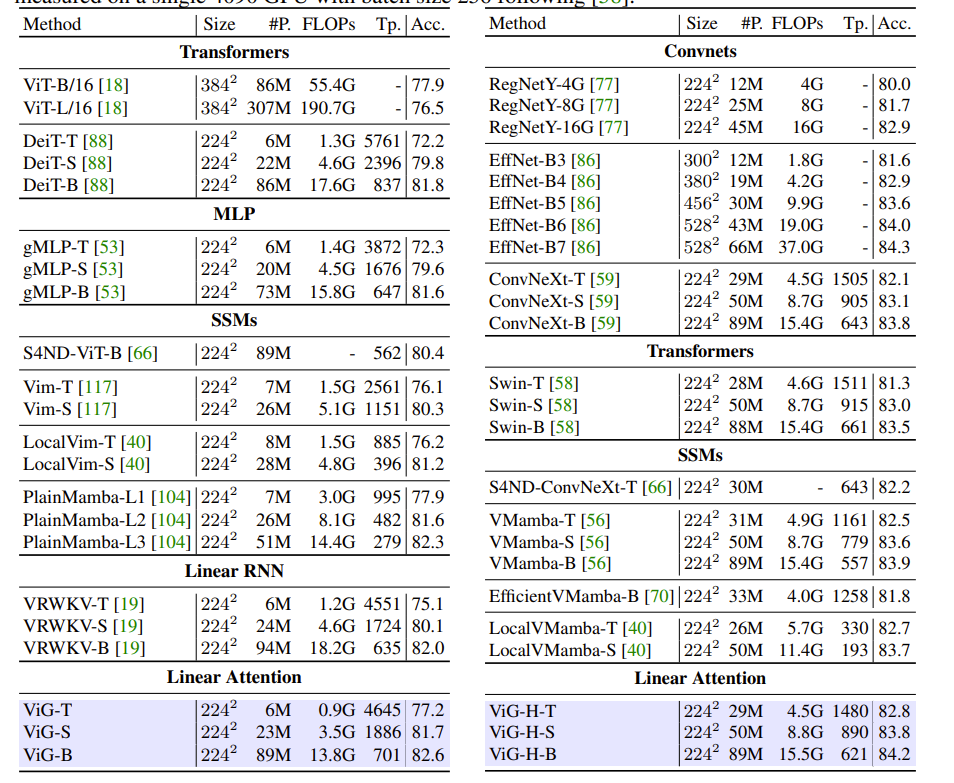
在 ImageNet-1K 上进行分类实验,其结果如下:
目标检测
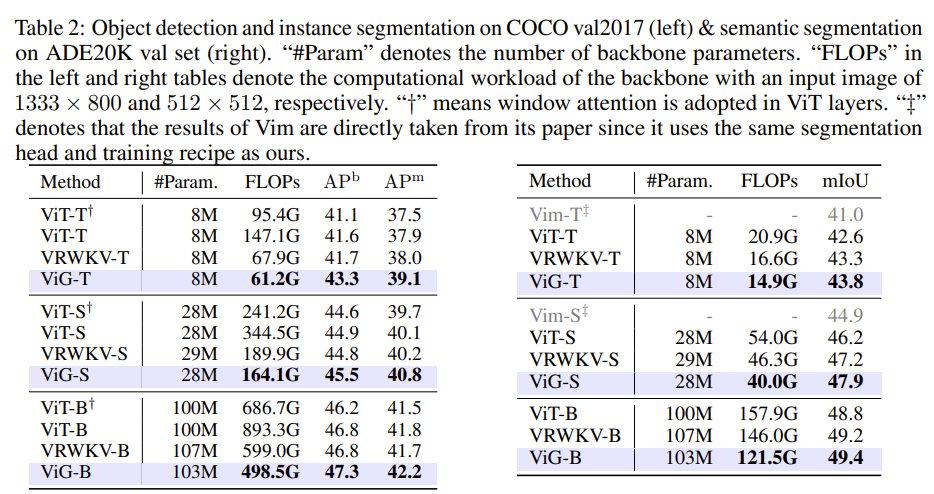
在 COCO 2017 数据集上进行了目标检测和实例分割实验。使用 Mask-RCNN作为检测头,并按照 VRWKV 将 ViT-Adapter集成到我们的普通 ViG 模型上。
语义分割
我们在 ADE 20 K数据集上进行语义分割实验。我们使用 UperNet 作为分割头,并采用 ViT-Adapter,按照 VRWKV的方法,将我们的普通 ViG 适配用于分割。
语言分割为上图的右图所示。
消融研究
ViG 的有效性
将 ViG-T 与 Vim-T、VRWKV-T 和 DeiT-T 进行比较,测试了从 224×224 到 2048×2048 逐渐增加输入图像分辨率的完整模型。表明:该架构相对于 ViT 的优势随着分辨率的增加而增长。
总结
介绍了一种名为 ViG 的新型视觉骨干网络。这个网络通过引入门控线性注意力(GLA)机制,解决了传统 Transformer 和卷积神经网络(CNN)在处理视觉任务时的局限性。具体来说,ViG 能够在保持全局感受野的同时,以线性复杂度进行计算,这意味着它在处理大规模图像时更加高效。
ViG 的创新之处在于它的双向 GLA 建模和 2 D 门控局部注入机制,这使得它可以同时捕捉到图像的全局上下文信息和局部细节。这种方法显著提高了视觉任务的准确性。此外,作者还特别设计了硬件感知的实现方式,以减少额外计算方向带来的开销,从而提升了整体效率。